Securing your secrets: Credential management
Secrets and credentials are everywhere, we use them to access third party systems. Securing secrets and protecting our credentials and passwords is not a trivial matter. So much so, that a major theme throughout any software platform or technical product is Credential Management. This article dives into everything you need to know, the issues with current strategies, and recommended solutions for improved security of credentials.
What are credentials?
In any software, platform, or application that involves more than one user, you will have to deal with authentication. And when you have more than one service or microservices, you will have to deal with credentials. That's because with multiple entities comes the interaction and integration between those entities.
We need clear identification so we can ensure that the appropriate caller has the correct authorization for the actions they want to perform. An example would be when your application needs to integrate with a third party service provider, like AWS, GGP or a payments provider, such as Stripe. Or when technical users of your application interact with your application's API, you'll need to provide them a way to securely access their resources. Lastly, you might have multiple internal applications or services that communicate with each other. This last one is heavily covered in-depth in Machine to Machine Authentication.
In any of these cases, there is a need to identify which user is which, and more importantly--authorize those users to the API, so that the right user has the right access at the right time.
To do that, we create and exchange credentials. And when I say credentials, I mean passwords, secrets, api keys, anything that is used for the purposes of authorization. For simplicity, in this article we'll refer to them as Credentials.
Why is this important?
It probably goes without saying, it's important to keep these credentials secure because malicious attackers will use any opportunity they have to infiltrate your applications or impersonate you to gain access to your data persisted with third party providers. When we add mechanisms to secure our endpoints, unfortunately attackers will use these same strategies to try to compromise our credentials, impersonate us and our users, all to gain access to whichever system we are trying to protect. This means the mechanism we pick is critical.
For instance, if you are using a third party payment provider, and you have an API key for that provider, they may try to compromise that key and use it to pretend to be you and withdraw all your funds or make malicious purchases on your behalf.
Credential management today
Today, in your application you are almost certainly using credentials of some form. And to generate these credentials, you probably have come to a screen that has a click here to generate an API key. Then you would take the generated result and store it somewhere. These are exactly the sort of credentials this article will focus on.
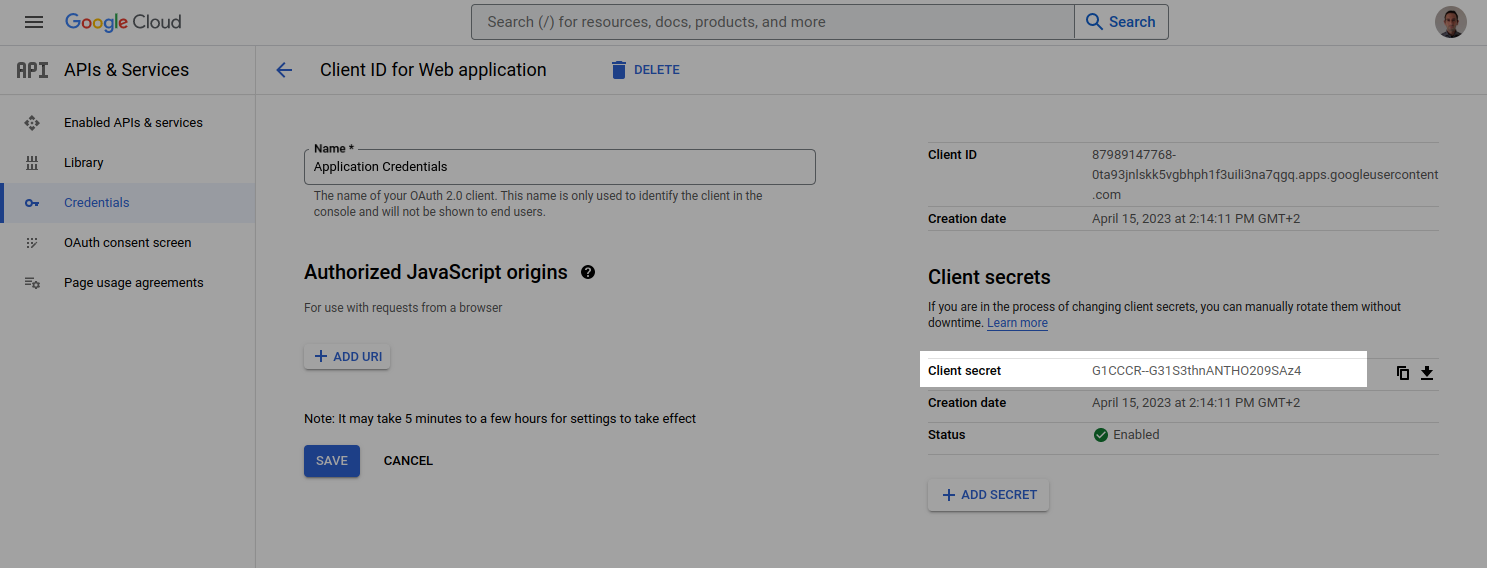
You end up on this sort of screen when you need to create those credentials. The full flow is:
- You go to the Service Provider's UI, and click some buttons, and end up on the screen above.
- Then, you click the copy button to get the credential out and put it in plaintext somewhere, usually using an IDE.
- This likely ends up in a configuration file, which gets deployed using CI/CD such as OpenTofu, Terraform, or Ansible.
- From there, it ends up in production. Production uses that credential to authenticate back to the Service Provider's API.
- The Service Provider validates the credential and your production system gets access to the necessary resources.

What's wrong with this flow?
Seems simple enough, right?!
However, every component we have, is another place that we have exposed our production credentials to, and they are exposed in plaintext. That means, every single additional technology we add, every service we introduce, is another exposure location. Every component can contain their own vulnerabilities, and therefore every component, is another opportunity for attack.
We have to eliminate as many sources of potential compromise as possible. And when you create credentials for your users and customers, you are responsible for their security as well.
Reviewing the credential creation process above, you can probably already see many potential opportunities for a malicious attacker to compromise those credentials. Let's jump into the flow to see where those potential sources of attack are and what we can do to reduce or eliminate them.
1. Generating the credentials
When an engineer on your team navigates to the service provider UI portal and copies out the credentials, they've already encountered the first exposure location and opportunity for credential exfiltration. Their browser could be compromised. It's possible that the browser itself has been modified or replaced. Is your browser actually the one that you installed? Did you install it from a legitimate source? Did you ensure that the hash of the binary running on your machine matches the expected binary hash from the provider?
Since the credential is visible in the browser that means it is exposed, and is available for attack.
Alternatively, even if the browser is secure, how about browser extensions instead. Extensions often have access to all the data on a website. How many of us have extensions installed and running in our browsers? Have you validated the source code of all the extensions you have installed and made sure that the permissions you have granted them are limited to only exactly what they need? Most concerning of all is that extensions auto-update themselves, which means even if they aren't malicious at this moment, we can't be sure that they won't turn malicious in the future or be sold to a malicious third party.
2. Our development machines
Then we pull down the credentials to save them. Our development machines are the next source of exposure. And potentially there is some malicious software running on your machine, waiting for that exact moment when you have the plaintext secret displayed. When you actually click copy on the credential, some malicious software could be running as a background service waiting to copy credential from the clipboard and send the data to an external server. So every time you copy something, you are exposing that data to background services.
This might seem far-fetched, but in May 2023, this is exactly what caused the massive breach at LastPass, a once major password manager. An operations engineer was running some vulnerable software on their machine. The attacker compromised their sessions, so that they could access all the LastPass user password vaults.
3. Using an IDE
Now that the credentials are on our clipboard, you need to paste them somewhere. Usually, that's the IDE. Well, the IDE that you are using could have been compromised in the same way that browser was. Have you validated that the hash of that binary is accurate? Or perhaps you have extensions installed in your IDE. When was the last time you validated the source of the extensions that you've got there? Often, right as you are trying to solve a very difficult coding problem, the IDE might pop-up a Clippy-like dialog and say "Hey have you tried installing this extension pack"? Since you are busy trying to solve your problem, you might not pay too close attention to what is in that extension pack.
And that's exactly what happened with the Darcula VS Code Theme. Wait...or is the official theme called Dracula? See there is a very commonly used Dark theme, which has a corresponding VS Code extension, but which one is the real one and which one is malicious? Darcula is a very cleverly named theme, that sounds like the right one, but is it?
Likewise, a similar source of compromise could exist for your installed cli commands, or if you are using git or some sort of git UI, well that's another opportunity for potential compromise. For your desktop or laptop, the operating system and your hardware are further opportunities. Did you check the signature of the installed OS when you got it and that there aren't any malicious physical chips installed on your motherboard? Would you know? The list actually goes on and on, but I'm going to stop here for the sake of time you get the point.
Everywhere involving you as an engineer and your system is a massive attack vector.
4. Compromise on your Git Server
You want to get that credential to where it needs to be, production. The credential goes to your Git server, hopefully GitLab or GitHub. But if you've picked up another solution, that too is a source of exposure. Here's a critical vulnerability GitLab just patched where attackers were able to run jobs with access to any user's identity. Further, how do you even know that you are connecting to the correct Git server and that server hasn't been compromised?
And even if it hasn't been compromised, let's think about all the people that could have explicit access. If your credential is saved in plaintext in your source, then everyone that has access to your source code either directly or through your git server, also has access. That's most notably the other engineers on your team.
Additionally, when using any managed SaaS solution, the operation engineers of that SaaS company, as well as the technologists that work on the infrastructure of that solution, and everyone with access to their logs, could all potentially have access to that credential that you've stored there. And while a company might have some sort of certification which promises "that there is a policy in place", a Git server solution does not have purpose built credential management solutions that are focused on security. I don't want to trust a company whose core competency isn't credential management to handle my sensitive credentials.
5. The CI/CD Deployment Pipeline
Okay. So now it's in git, and you're running some CI/CD, that's another opportunity. CI/CD could be executed using some sort of managed Git server actions, or a separate solution altogether. If you are using an Infrastructure as Code system like OpenTofu, Terraform, or Ansible, that's another exposure location. The credential is exposed to your pipeline. Which means it is exposed to every tool used in your pipeline. Anything you are running such as code spitting, code bundling, web packing, and code quality related validations all have access to the pipeline credentials.
And all of these exposure locations exist even before the credential ends up in production!
6. Production Application Runtime
Then finally, the credential gets into production where it is safe, right?
Unfortunately not. Your service's own interface might be vulnerable to code injection attacks, utilizing the publicly provided API. Keeping your API undocumented unfortunately doesn't help at all. And naturally, you've pulled in various software dependencies from different binaries and different available libraries. Open source has come under much scrutiny recently, and it appears to only be getting worse. The most recent attack was perpetrated in the XZ linux package via an SSH backdoor.
That's just the software side. You are most likely running your service in a cloud provider or potentially on prem, that means the provider's operation engineers themselves have access to the infrastructure running your service, and therefore access to the credentials for your production environment.
And since you are awesome at observability and care about the reliability of your production service, you're writing tons of logs, likely including every request that comes in from any users and every response goes out to any service. Well that third party service provider is accessed via HTTP requests, which means your logs will be capturing those credentials. Anyone who has access to those logs, even if they don't have direct access to that credential, the source code, or the service itself, will have access to whatever is in those logs. If you are then shipping those logs to a log provider or data analytics solution, you are again exfiltrating the credential yourself.
This problem is so severe that source code providers GitHub, GitLab, and others have dedicated secret scanning programs to ensure that when you inevitably leak your credentials, you will be alerted. They may even automatically revoke those credentials for you. Of course Authress is included in these programs.
The full list of vulnerabilities
Okay. So that's a lot. However, now that we know where the exposure locations are, we can implement targeted solutions to eliminate potential attacks. The collated list is:
- The Browser
- Engineer's System
- IDE, Plaintext
- Git server
- CI/CD Pipeline (IaC)
- Other Engineers
- Application Infrastructure + logs
Part 1: How do we do better?
Okay, let's start by taking a look at the first thing we can do. Thinking about how we're managing those credentials right now, an engineer is just pushing them to production in plaintext. Now, I'm sure you are thinking, no one stores their credentials in plaintext. But that no one, isn't really no one. Every month we are reminded that someone did this, and that there's a publicly accessible cloud bucket out there with credentials. The negligence awards list is so long that there are articles dedicated to it, a good one is in this GitHub repo.
Environment Variables
The first thing that probably comes to mind regarding improvements to this credential management process is using Environment Variables.
Environment variables are fantastic because they allow us to directly inject configuration into your production environment. You might be thinking maybe they can help with credentials as well.

How the environment variables actually get to production is still an open question though. We know how to reference them once they are in production, but they don't magically just show up there. So Environment Variables aren't a full solution in and of themselves.
In order to actually use environment variables we need to store them somewhere. Depending on which Git Server you are using, it might offer you some sort of Git secrets management. For instance, here is the one offered by GitHub:
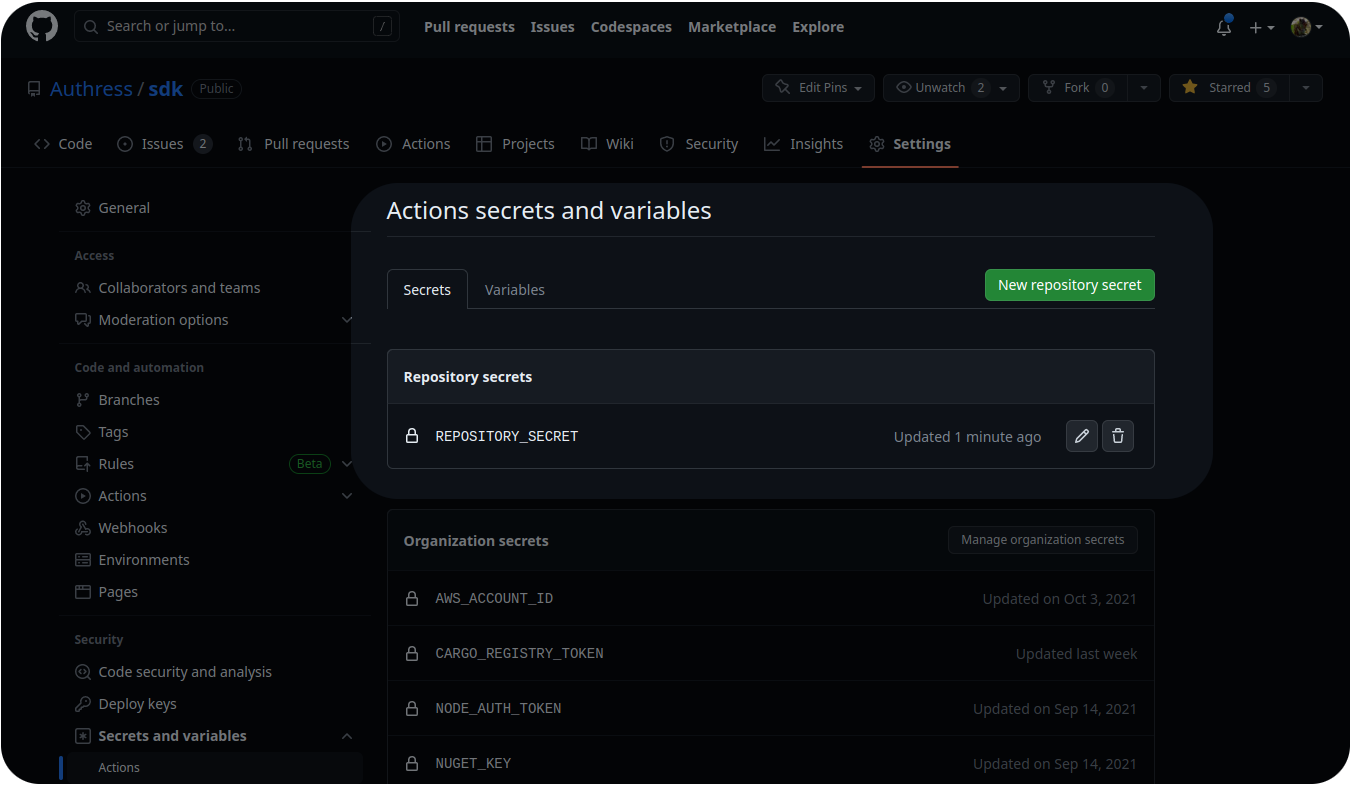
With using the GitHub secrets repository, we no longer have the secrets in plaintext, and it is no longer visible to everyone that has access to the source code.

Here, you're getting the benefit of using the Git secret repository. You aren't sticking them just anywhere. GitHub, for instance, has a dedicated secrets management solution, which makes you think that they may have thought at least a little bit about what they're doing. But as we're introducing a new system, that new system is a source of exposure and therefore an opportunity for credential compromise.
More importantly, if you have actually ever done this in practice, you'll notice that this flow isn't complete. You can't just put the credentials as an environment variable in GitHub Secrets and have them magically show up in production. We actually need to introduce another component. A component that would actually create and inject those environment variables at runtime into your production application.

To make environment variables work in production we'll introduce the Application Control Plane. The requirement of this additional technology component allows us to use environment variables. But the cost is it's an additional exposure location, so therefore another place that is vulnerable exists. So let's review the list of exposure locations while using Environment variables:
- The Browser
- Engineer's System
- IDE, Plaintext Git Server Secrets
- Git server
- CI/CD Pipeline (IaC)
- Other Engineers
- Application Infrastructure + logs
- Application Control Plane
We might think we get some improvement using the Git Server Secrets, but if we count up the number of exposure locations, we can see that using Environment variables actually increases the number of locations, not only did we not improve over the original flow, we actually made it worse. Using environment variables is a mistake.
We have to do better, and one solution might be using a Secrets Manager.
Secrets Manager
Secrets manager is a service often available from your cloud provider. There are also third party SaaS as well as open source. A secrets manager is a dedicated technology that provides secrets-input usually via a text input box. Additionally, they usually support configurable access controls for the secrets, record an audit trail, and may even help with credential rotation.
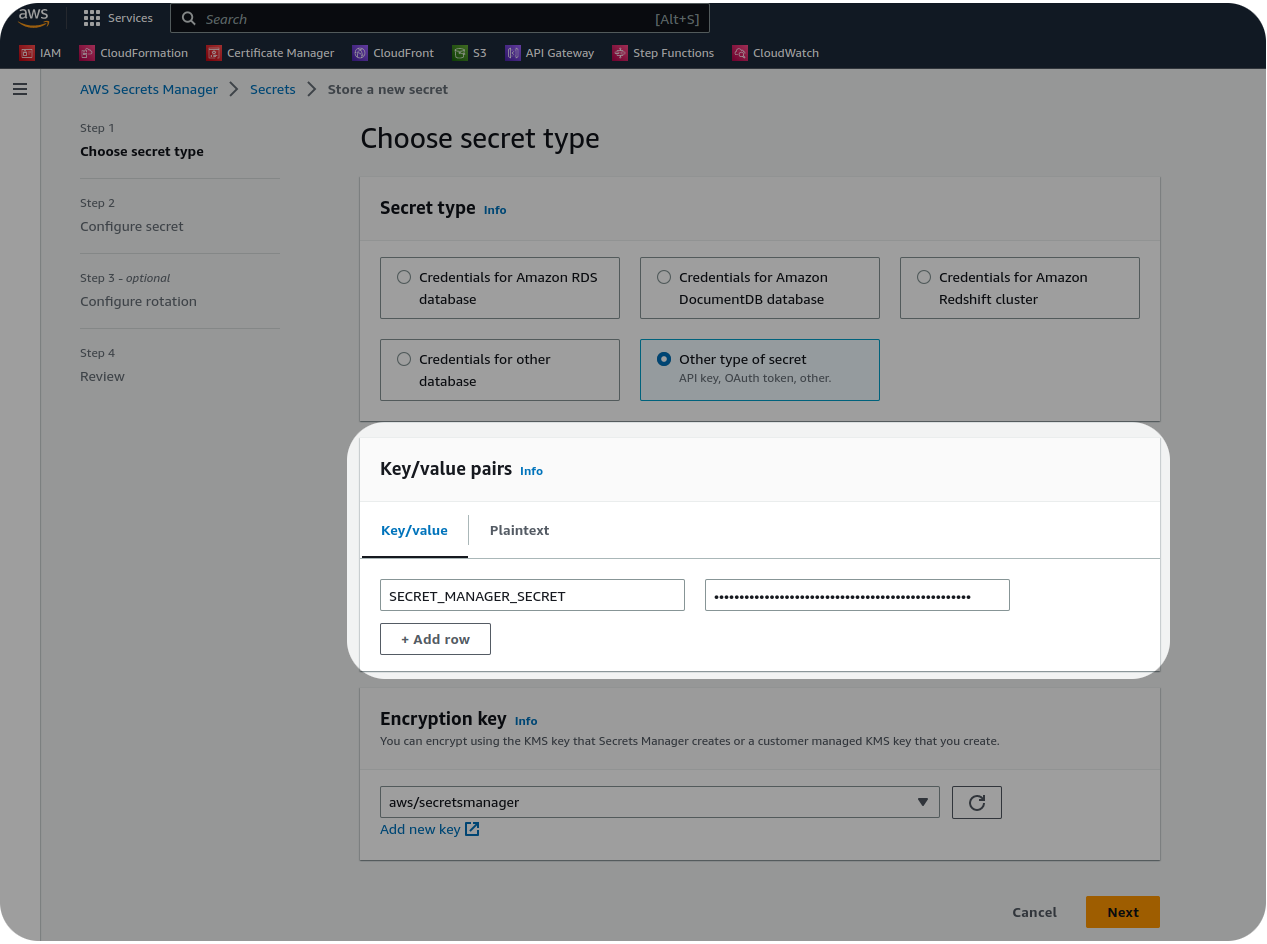
The Secrets Manager works accepting secrets that you push to it. It then stores the secrets in a Secrets DB. Later when we need the secrets back, we can call the interface, fetch the secrets from the DB, and then use them where necessary.

With the Secrets Manager in our toolbox, let's see how we can layer it on our Environment Variables technology. Instead of having to use the Git Server, you can directly inject the credentials from the Secrets Manager into the CI/CD part of your pipeline.

If you take a long look at this flow diagram, you may be able to identify that you do not in fact need to have the credentials in the CI/CD flow at all. As a matter of fact, these are production credentials. They should never be exposed to any system that is not fundamentally using the credentials. This means you only need them in production, not the IaC provider, be it OpenTofu, Terraform, AWS Cloud Formation, not your code quality tools, not your CI/CD pipeline, nor anything else. None of them need to know about the production credentials. Can we put them somewhere else where only production can directly access them?
Depending on your cloud provider and the application control plane you are using, you might be able to utilize a direct integration into your Application Control Plane:

There might even be "great support" for doing this in your cloud provider. However, you don't actually want to do it. That's because as long as you are using environment variables, you aren't getting the benefit of using the Secrets Manager at all. We've migrated from using Git Server secrets to storing them in a secret manager, it's practically identical. You haven't really changed anything. All the opportunities for compromise are just replaced with this new service. Like this, there's no improvement nor a reduction to our attack surface.
Most importantly, as long as you are using environment variables, you require the Application Control Plane; that unsightly object that created an additional exposure location within our stack. If you want to remove it, we simply need to stop using environment variables. And because the Secrets Manager supports an API, it can be directly called from production. So let's do it:

Now that we've completed the Secrets Manager integration into our stack, let's review our exposure list:
- The Browser
- Engineer's System
- IDE, Plaintext, Git Server Secrets
- Git server
- CI/CD Pipeline (IaC)
- Other Engineers
- Application Infrastructure + logs
- Secrets Manager Interface
- Secrets Manager Control Plane + DB
Since we haven't changed how we are getting the credentials, the Browser and our Systems are still in play. But on the plus side, we've completely eliminated the IDE, Git Server, and CI/CD Pipeline. Improvement Finally! However, since we are using a shared system and interface, other engineers on our team will still have access. Additionally, we haven't changed the fact we are using the credentials in production, so our infrastructure and logs are still relevant.
Unfortunately, we've added a new component, the Secrets Manager. So we need to consider it as an additional exposure location. At least it is purpose built to handle credentials, but someone has to run it. The operation engineers that run that Secrets Manager will have access to the secrets, and worst of all there is a Secrets Database out there with all your secrets. If that gets leaked an attacker can gain access and impersonate all our users or access our sensitive data in our third party systems. I don't want that, but it's there.
If you stop here, you've done a minimal job. Secrets Manager provides an improvement over the original flow and much more over using environment variables in any way. If you've implemented a Secrets Manager to manage your secrets and directly integrate with it from production, give yourself a pat on the back, nice job!
Key Management Service (KMS)
Given the number of attackers we have to deal with today, we need to do better. While we've eliminated a bunch of the previous attack vectors, we've added a new service with a database that is vulnerable. The Secrets Manager's attack surface is anyone who can access the control plane of it, its logs, and its database. Further, the secrets manager interface is accessible by the other engineers on your team. Frustratingly, we still haven't even eliminated the vulnerabilities from our development machines.
To this point we haven't introduced encryption. By doing so, we can eliminate many of those access points using a Key Management Service (or KMS).
So let's discuss how a key management service works. The Key Management Service allows you to give it credentials. It will encrypt the credentials and return back to you encrypted ciphertext. The Key Management Service does not store any data though, so after returning us the encrypted credential, it discards the original credential from memory. Therefore, there is no secrets database. That means, we need to persist the encrypted credentials on our side, and to do that we'll commit them to our source code using git.

After that, we'll use our standard CI/CD process to get the encrypted credentials to production. From there, we execute the reverse flow. We pass the encrypted credential to the Key Management Service, which returns us back the decrypted credential.

With encryption at our disposal we can plug the Key Management Service into our pipeline and see how that can work in practice:

- The Service provider generates the credential and passes it to the service provider UI.
- We copy out that credential from the UI and pass it to the Key Management Service.
- KMS encrypts the credential, returns us the encrypted credential, and discards the plaintext version.
- We take that, commit it to git, and use the CI/CD pipeline to deploy it production.
- From there, production calls KMS with the encrypted credential to decrypt it.
- We get back the decrypted credential, and use it to authorize our production environment to the service provider.
With the Key Management Service successful integrated into our pipeline, let's see how that changes things:
- The Browser
- Engineer's System
- IDE, Plaintext, Git Server Secrets
- Git server
- CI/CD Pipeline (IaC)
- Other Engineers
- Application Infrastructure + Logs
- Secrets Manager Database
- + Source code audit tools
- + Easy credentials rotation
Well that sucks, we still have the browser and the engineering system exposures in play. However, because the decrypted credential does not exist as an environment variable and it is also not stored on disk in the production system, we continue to keep the improvements we made earlier via the Secrets Manager. However, since we are still using a shared system, other engineers will still have access to the credential and exposure there offers an opportunity for vulnerabilities.
There is a noticeable improvement with this shared system though. Unlike the Secrets Database, in order to gain access to the credential there are two pieces of information required, an attacker needs both access to the Key Management Service and access to the encrypted credential in source code. This provides a significant improvement over the previous single access location. I'll say that again, there's nothing persisted in KMS, so in the case that KMS is compromised, if you are using a KMS data key, then your credential is never exposed to an attacker. Also because we will often decrypt the credential directly in production and then discard it after use, we can likewise eliminate the Application Infrastructure exposure location.
Lastly, because we are using source code to store the credential, we get the benefits of our developer tools. Our IDEs work great for this, and we also get the benefits of the versioned source code as an audit trail for changes. If you ever find yourself in the unfortunate situation of needing to rotate a credential, that's a single git commit and now the new credential is in production. Done! There's no complex async background process that has to be run to get the new credential to production. If it is in the source code, it will be in production.
Current learnings review
- Environment Variables don't work - They are literally the worst, you should never use environment variables for credentials. Realistically environment variables and credentials never belong in the same sentence...I guess besides to say that they don't belong in the same sentence.
- Secrets Manager is okay - This is the minimum work you need to do to protect our sensitive credentials
- Committing encrypted secrets with git utilizing a Key Management Service is the best we can do. And it is the best as long as we don't control the service provider. When we are just given a shared secret in the form of a random string of characters that we need to return back to the service provider later, we literally cannot do better.
Part 2: The Service Provider
At some point, we'll likely have technical users who will want to access their data using our APIs. And that means we need to provide them credentials, which makes us a Service Provider. Also, only considering the client side part of the credential management process doesn't give us the full picture, as we are missing another whole set of potential vulnerabilities.
So if you are the service provider, what additional exposure locations do we have?
Credential generation
The first part of the service provider side we need to consider is how to generate the credentials. The standard strategy a lot of service providers go with, and the one you'll find most common when you become the service provider yourself, has the pattern:
- The Service Provider API generates the credential using some sort of credential generation function. Potentially a random string of characters.
- Then it makes it available in the UI to give the users of the API access to the credential.
- To actually handle credential validation, the service provider stores the credential in the DB.

As you can probably guess from other aspects of this academy topic, there are vulnerabilities everywhere.
Just as there were issues on the production side susceptible to supply chain attack via the libraries and dependencies being used, the Service Provider is still susceptible to those same vulnerabilities during credential generation.
Further, anyone that has access to a source code prior to production deployment can potentially change the credential generation strategy. Or if there are fundamental issues with it, they can use their understanding of how the credentials are actually being generated, used, and validated to use that knowledge to directly impersonate users by simply guessing what credentials the strategy will generate.
For instance, maybe the credential is just a random number that wasn't securely generated nor a UUID or maybe it is something attached to the user's account number generated at a specific time. Guessing when the user's account was created, the user's account ID, or when the credential was generated might be enough to guess a valid credential.
And of course in order to validate the credential during incoming requests, the credential has to be persisted in the service provider's database. That's a single place with all your users' credentials. That's a huge target for attack. And by accident, it can also be leaked. Figuring out if they have been leaked is not a trivial activity. Detection Engineering is an extremely challenging problem. With credential leaks, you likely won't find out until an attacker attempts to use the leaked credentials to impersonate your users or after your sensitive data has already been stolen.

And that's just the part of the service provider API that is relevant during credential generation. Next, the service provider sends those credentials to the UI where they will be displayed to the user. Remember, we need to let our users access the generated credentials. Well, if credentials are shown in your UI, that's another exposure location. And if you have a vulnerability there, then those credentials will be compromised. For example, with a Cross Site Scripting (XSS) vulnerability, an attacker could phish your users, have them end up on your UI, and automatically exfiltrate generated credentials back to the third party. Usually when this happens there is very little information even communicated to the users. An example is available from an auth provider who had a serious XSS vulnerability in their admin UI.
Further, most UI apps have some instrumentation running on the browser side. So third party tools that you're using--Google Analytics, Sentry, DataDog, or anything else in your UI--are exposing those credentials to that third party system through the app's analytics and logs. That's another location a malicious attacker could use to obtain our users' credentials. If there's an issue or vulnerability in your instrumentation, functionality, or that third party then an attacker can exfiltrate the credentials from there.
For many apps, we really care about the user experience being provided to our users. That's certainly true at Authress, User and Developer Experience is one of our core competencies. However, that may mean you are also tracking everything that users see and do in the app. The credentials show up on the screen when the user goes there to click copy, which means your credentials will be exposed to those tools that do screen recordings.

At this point we arrive at the client side part of our flow. We've talked extensively about this in Part 1 of this article, so we already know what's there. We're still using the Key Management Service, to get the encrypted credentials to production. Once the credentials arrive at production, we use them to authenticate and authorize back to the service provider. However, being back at the service provider side is a second opportunity to expose the credentials all over again.

Since we're back at the service provider, all the same set of service provider vulnerabilities exist again. We can rehash all the same exposure locations as before--the credentials come in through our API, so we can end up logging them to the logging solution or APM tracking solution, which may have additional and separate access. Or they'll end up in our analytics if we aren't careful. The recent data breach at Snowflake is an example of this, and is likely to snowball to a number of other breaches yet to come.

Complete exposure locations
Having completed the review of all the exposure locations on the service provider side, let's form a complete list. We have the three previous ones from the client side:
- Engineer's System
- Production Runtime
- Other Engineers
And the new ones from the Service Provider side:
- Service Provider DB
- The Browser + Service Provider UI
- Service Provider Logs + Infrastructure
There are potentially quite a few ways we can start tackling this new list, but most of the solutions will only handle some small part of the total attack surface. And as long as we don't take a holistic review of what we are doing it will be hard to get very far. So instead, it makes sense to target the part of the process that will help us get the furthest distance. And to do that, we'll need to revise the credential generation and verification process.
But before we do that, now that we have a good handle on the exposure locations and vulnerabilities when we get this right, let's see what happens when we get it even slightly wrong.
Credential verification issues
In the generation process described above, we are required to store the credentials in our database so that we can verify incoming requests from users are actually authorized. Having stored the shared credential in the database, you can pull it out every time you receive a request and verify that it matches the one sent in the request. That likely means having some code to do it:
if request.api_key == database.stored_api_key
However, if you have exact code in your production application, you actually have a critical security vulnerability at this moment. This code that directly compares the API key to the saved version is susceptible to what is known as a Timing Attack. A timing attack is a clever brute force strategy that utilizes the insecure direct equality comparison to generate valid credentials. If you have code similar to this, you are actually telegraphing to attackers how to construct valid credentials that will work with your API. Determining how to execute that attack is out of scope of this article. However, to defend against it you'll need to update your equality comparison to one that can defend against timing attacks.
Most languages and frameworks support a secure strategy to do this, which is known as Timing Safe Equals.
if crypto.timing_safe_equals(request.api_key, database.stored_api_key)
Only this can prevent the timing attack.
It's interesting to note that not every language makes this easy to execute, which means it is more difficult to write secure application code to do credentials verification in some languages than others. In essence, some programming languages are more secure by design than others. That's an interesting thought, depending on the language of choice, you could more easily fall prey to a timing attack and having other insecure application code. The language you use can have serious security implications.
We also know that storing the plaintext credential in the database makes our database vulnerable to attackers. These credentials are very similar to user passwords, except they are much more powerful as they usually allow unfettered access to our third party systems. At the very least we should secure them with the same level of security practices and concern we apply to user passwords. The corollary here is that we know user passwords are unsafe by design, what does that say about using shared credentials? Today, the least insecure strategy is using argon2id with memory or cpu hard resistance. However many implementations that attempt to secure credentials and passwords fail to achieve even this level of security, as they unfortunately use bcrypt or a strategy even weaker.
Assuming we correctly use argon2id, you would verify the incoming request credential by utilizing the salt and hash from the database, rather than the plaintext credential:
if crypto.timing_safe_equals(request.api_key, database.stored_api_key_hash, database.stored_api_key_salt)
This coupled with the exposure locations associated with the default credential generation strategy suggested earlier in this section, we can see that it is challenging to get this right in any way.
Speaking of not getting it right, let's take a second look at the GCP OAuth Client Credentials configuration screen from before:
You might notice that every time you return to this screen the same credential is shown in the bottom right hand corner. Every time you refresh the screen, the same credential is displayed. Every time another engineer on your team visits this screen, the same credential is displayed. This means that this credential must be persisted in plaintext in a database somewhere. Google had to persist this credential so that they could display it in plaintext back to us at any time. If it was hashed and salted, this would be impossible, they aren't using argon2id, they aren't even using bcrypt.
This means that Google has a database with all these credentials, in plaintext, in it. That's a source of exposure and can be leaked. If and when it does that means an attacker would then have full access to impersonate all the users attached to this credential, log in as them, and steal any sensitive data in your application for all of your users.
It turns out that we can spend a lot of time trying to get this strategy right, but what hope do we have if large providers that actually focus on security sometimes get it wrong?
Asymmetric Key Cryptography
Rather than trying to successfully navigate around all those problems, the best alternative is to instead use Asymmetric key cryptography. Now, I know those are some scary words, but I think we can work our way through it, and the result will be an easier system to secure and better protected credentials without all the pits of failure.
To implement asymmetric key cryptography, we'll need to update our credential generation function to use asymmetric key pairs. This can be done by including library or framework functionality in your language of choice. The high level implementation for the process looks like:
- We generate the public and private key on the service provider side.
- The public key is persisted in the database.
- The private key is provided to the user to deploy to production.
- At runtime the private key is used to sign a JWT.
- That JWT is then verifiable by your api by using the stored public key.

(If you aren't sure what a JWT is, it is a Base64 encoded JSON object with a signature. For the purposes of this article it could actually be any opaque access token. JWTs are the most common form.)
If we plug this into our flow as before, we can merge this new technology with our previous improvements we made on the client side utilizing a Key Management Service:
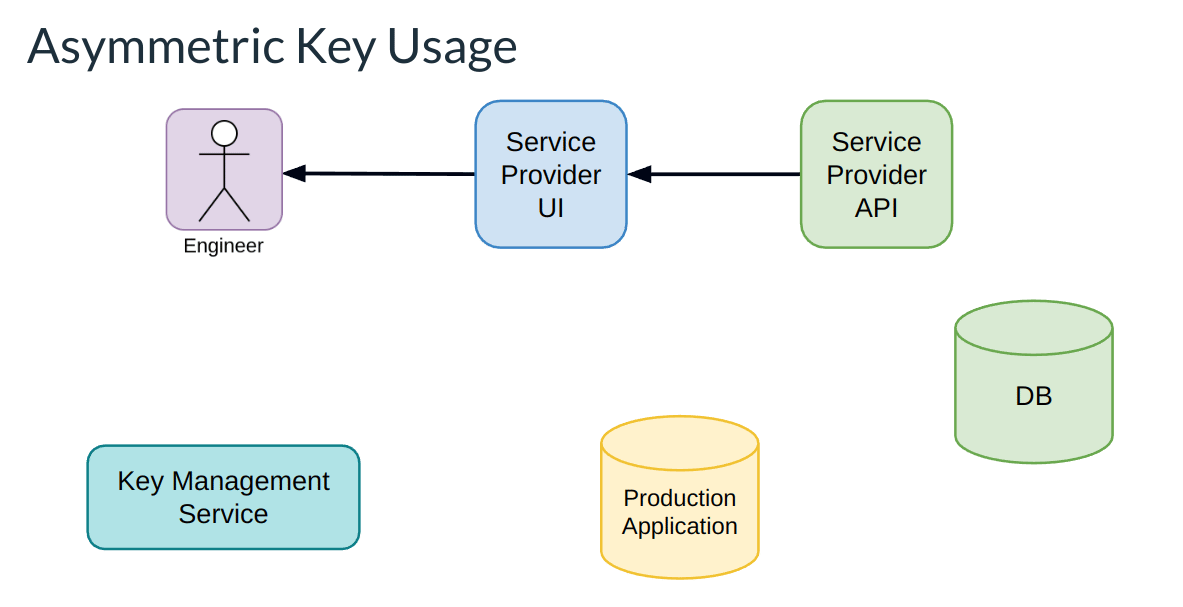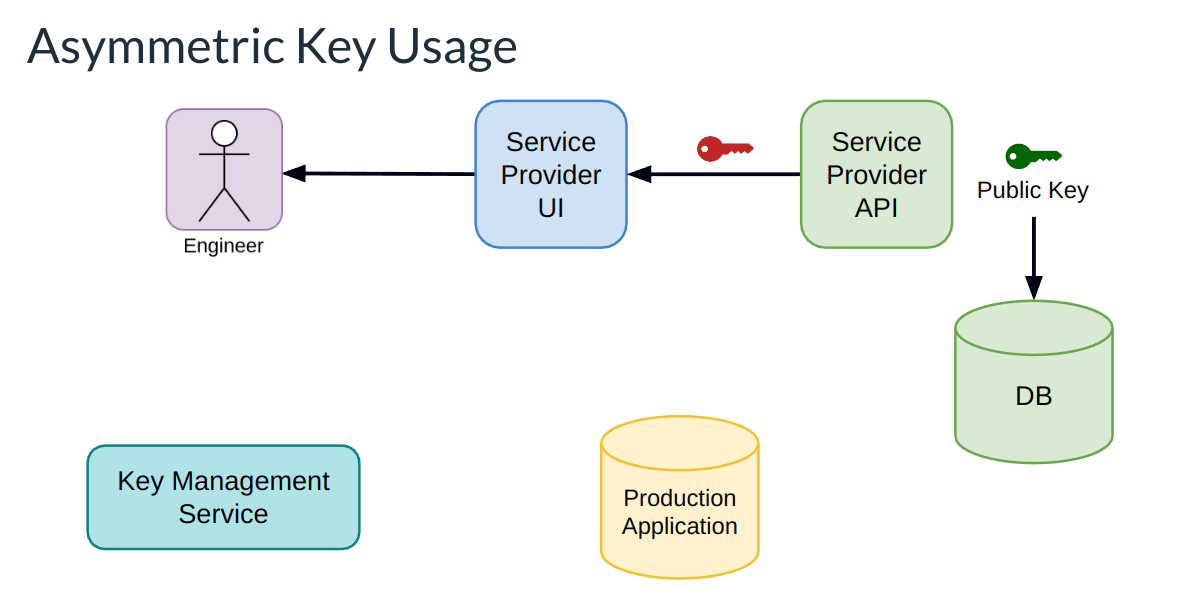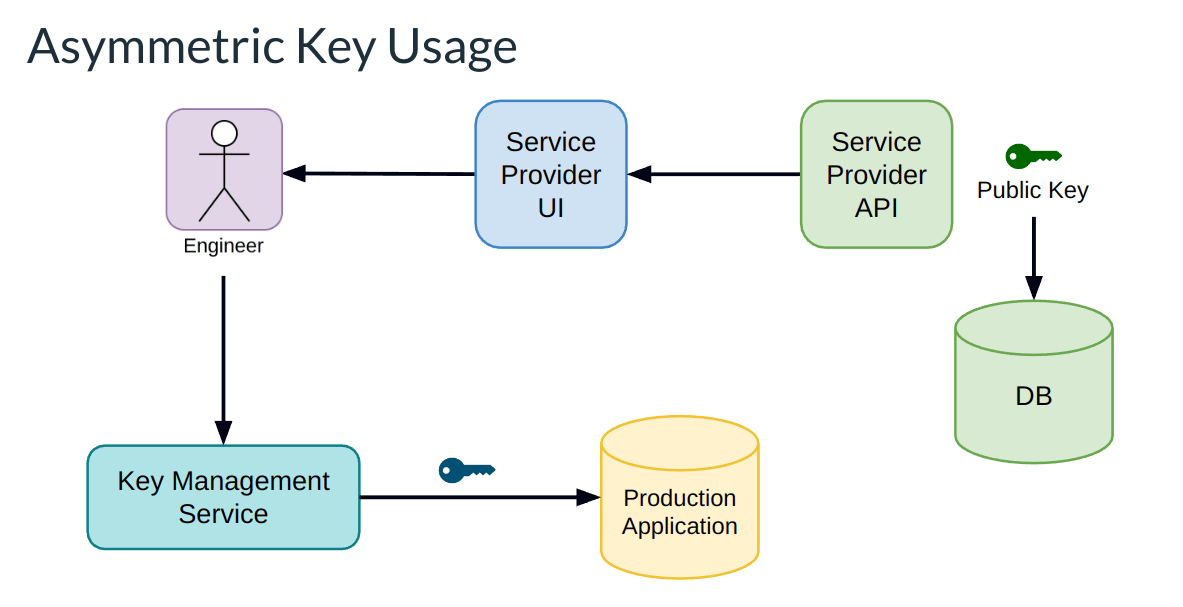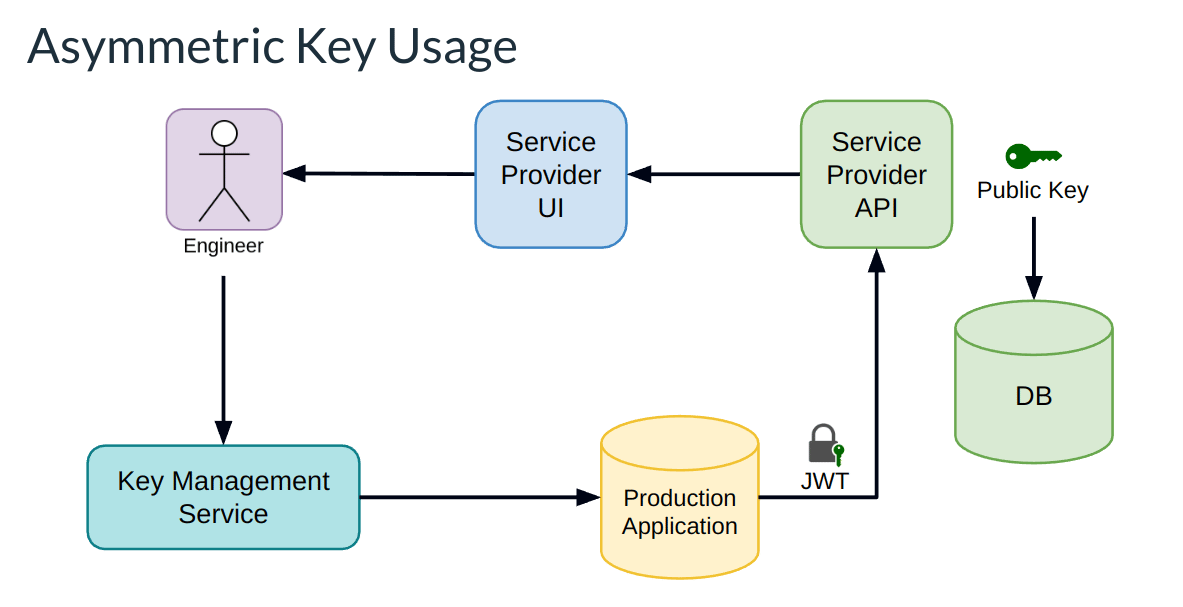
As we've taken this next step to introduce asymmetric key cryptography over easy-to-get-wrong shared plaintext credentials, surely this has to have some impact on our exposure locations.
- Engineer's System
- Production Runtime
- Other Engineers
- Service Provider DB
- The Browser + Service Provider UI
- Service Provider Logs + Infrastructure
So no changes on the client side, everything is still the same there. And that makes sense as we didn't change anything about how we are getting or using the credential. It's just the same Encrypted KMS Credential. However, we are able to eliminate the Service Provider DB as a source of exposure. The private key part of the credential pair is never persisted on the Service Provider side, which means that you can actually leak your whole database and there aren't any credentials there that an attacker can use to impersonate your users. If you leak your whole database all over the internet, you'll probably have other problems, but attackers impersonating your users isn't one of them.
Credential generation location
Looking back at the previous diagram, we'll notice that the credential is exposed in two locations, the service provider API where it is generated, and the service provider UI where it is displayed to your users. However, this credential is discarded from both locations after generation since the service provider only needs to store the public key:

This means an obvious improvement we can make is to push the credential generation backwards to the UI. From there we can have the UI generate the public and private key pair, upload the public key back to the service provider API, and still make the private key credential available in the UI.

Now, I know what you are thinking: That's ridiculous, we shouldn't be creating credentials in the UI. Well...if we look at this diagram and our list of exposure locations, we can trivially see that this is fundamentally more secure. It completely removes the exposure location of our Service Provider API from the picture. So that intuition fails us here.
However, why stop there? We can further eliminate the exposure location of the UI as well by pushing the credential generation all the way back to our technical users who wish to integrate with our API. This is known as Bring Your Own Keys, or BYOK:

With BYOK, our users will create the public-private key pair, upload the public key through the UI to the Service Provider API, while keeping the private key credential secure on their side. The rest of the flow is as we determined from before--Your users would call the Key Management Service encrypting the credential, commit it with git, and push it to production. From there, production decrypts it, signs the JWT, and then authorizes back to your API.
As the service provider, this only requires you to support asymmetric keys, which seems like a huge win. That amounts to basically supporting the upload of a public key from the users, that's it. If we aren't the service provider, then we just need to make sure that our third party providers support it, which to be fair not every service provider does. However, if there is a single takeaway here, that would be: if they care about security, they'll offer you BYOK, and if they don't, it is a clear indication that they haven't thought enough about making a secure product/application/platform.
Converting to the BYOK strategy must get us some improvements regarding the overall list of exposure locations, so let's see how it does:
- Engineer's System
- Production Runtime
- Other Engineers
- Service Provider DB
- The Browser + Service Provider UI
- Service Provider Logs + Infrastructure
Are we surprised? The engineering system as well as everything on the client side is still a vulnerability. But with this one simple trick, we have completely eliminated everything on the service provider side. That means supporting BYOK creates the most secure strategy for our users. If that isn't a good enough reason to support it, as the service provider we can consider how this provides a complete elimination of potential vulnerabilities on our side. For sure this is something that every one of your CISO and security teams would be jumping for joy over. We never have to worry about security vulnerabilities regarding credentials on our side at all. Success!
Part 3: Production
Can we go further?
Realistically the biggest vulnerable location is ours and our fellow engineers' systems. Which are still open for attack, because credentials are exposed there. So taking another step towards a potentially better solution seems logical.
On the other hand, until this point, we couldn't do anything. We were limited in our options. But when the service provider has taken the effort to make a secure system with BYOK, we are afforded another opportunity. So let's take another look.
Revisiting credential generation
From above, we were able to push the credential generation back to the technical users, or in the case of third party systems we integrate with--our engineers. Let's continue pushing the credential generation back further. To do that, we can have the production service decide to generate the public and private keys themselves. This pushes the generation all the way to production. Our systems would generate the credentials, encrypt the private key, and store it in our production database in a similar way you would secure it in source code. However, instead of the engineer doing it, the production service does it. And then it exposes the public key for verification. We can do this via some endpoint or in a log file, where an engineer can grab it, and upload it to the Service Provider.

- Production generates the public and private key.
- It exposes the public key so that it can be uploaded to the Service Provider.
- At request time, production uses the private key to sign a JWT.
- That JWT is sent with the request to the Service Provider for verification.
This is commonly known as OIDC auth, and is very common with CI/CD providers such as GitHub, GitLab, and others. It is of course something that the Service Providers still have to explicitly support, but more and more support this strategy. Some SaaS support it. Most Cloud Providers support it. Authress supports it. And as a service provider you can support it too.
No engineer ever has to have access to the credential. It's encrypted and stored in our database, and we can make it so that no one has access to the production database either. It looks like this could be the improvement we've been waiting for all along. Let's take a look at our exposure list:
- Engineer's System
- Production Runtime
- Other Engineers
- Service Provider DB
- The Browser + Service Provider UI
- Service Provider Logs + Infrastructure
Wow, we've pretty much eliminated everywhere the credential is exposed, finally!
...
However, there is just this one place left:

Production of course still has its own share of potential vulnerabilities. For instance, the cloud provider still has access to the running version of the service. The service itself could be compromised. What if someone injected bad code through one of our libraries or dependencies via a supply chain injection attack? That would compromise our production environment. Did you make sure all your packages were up to date and didn't have any security vulnerabilities? How about yet undiscovered zero-day vulnerabilities? Or maybe you are still using log4J and someone can write a malicious text entry which would log all the credentials that were being used by your production runtime to an external server.
Removing production access
So what if production didn't have access to the key either? What if it was stored in a physical piece of hardware? Well, it turns out you can actually get hardware devices which store private keys on their hardware and don't let you export them. They, of course, expose the public key when you need them. But the private key is totally secure. Your services don't have access to it, your source code doesn't have access to it. We can actually do that using a Hardware Security Module.
HSM
An HSM (Hardware Security Module) is a black box private key that does just that. It exposes only the public key, and encryption takes place inside that black box. There is no interface to expose the private key, this makes it cheap and easy to get encryption, and more specifically, get asymmetric key cryptography right with limited room for security issues.
Here are two common examples.


The first one is a TPM, which creates a root of trust on your machine. The second one is something we should all know, these are YubiKeys, often used for user passwordless authentication via FIDO2 or WebAuthn. I'm sure someone is going to call me out that these aren't exactly the same, but for the purposes of production encryption, they both work to that end.
Obviously there are the physical intrusion issues with either of these, but that exposure is far outside the bounds of credential security. And if you don't have sufficient data center security, then any security mechanisms we try to put in place at a software level are an illusion. If anyone could come and gain physical access to your production runtime, then having the credentials in plaintext is no worse than using a more sophisticated strategy. Let me repeat that, if you don't have sufficient physical security of your data center, then spending any time trying to improve your credential strategy is a waste of time. It is important to build a reliable and useful threat model before attempting to implement additional security mechanisms. There's a great video of just how terrible some data centers can be, and if this is an interesting topic to you, I recommend the AWS Data Center security whitepaper.
Now that we know what an HSM is and how it works, let's put it into our flow:
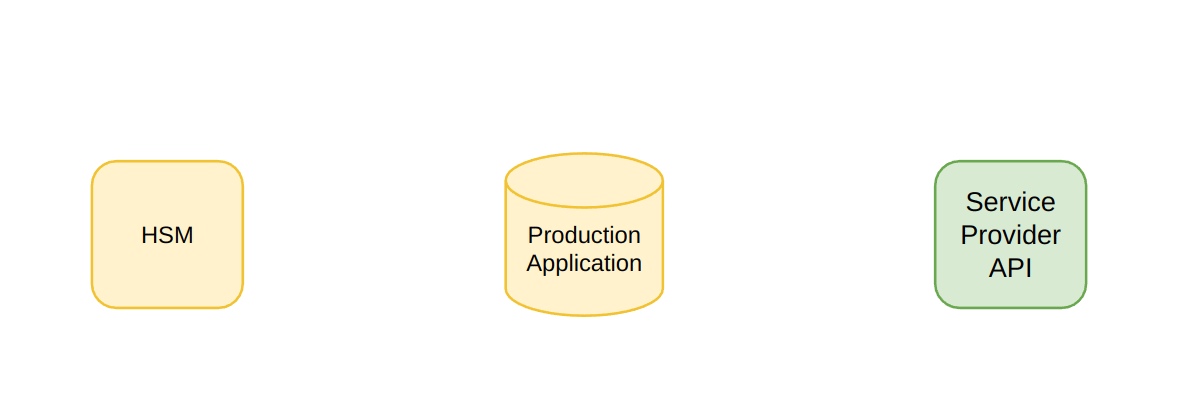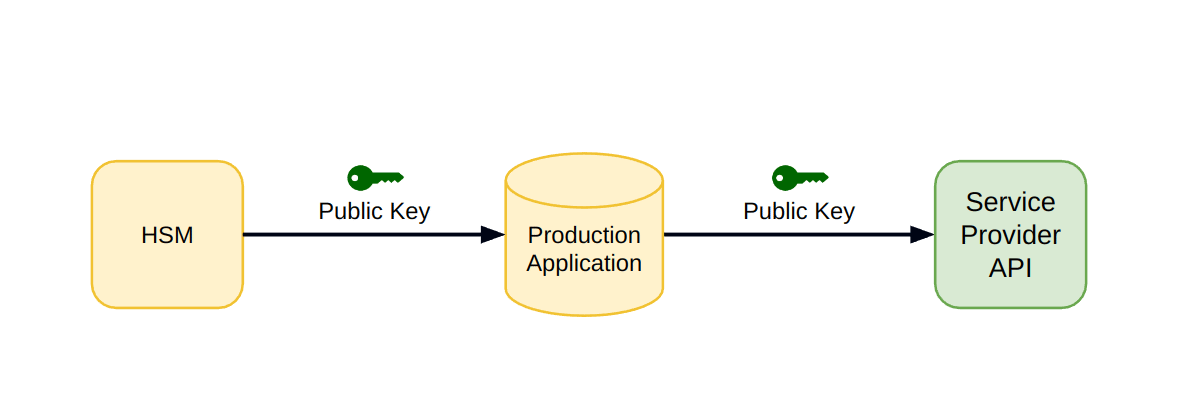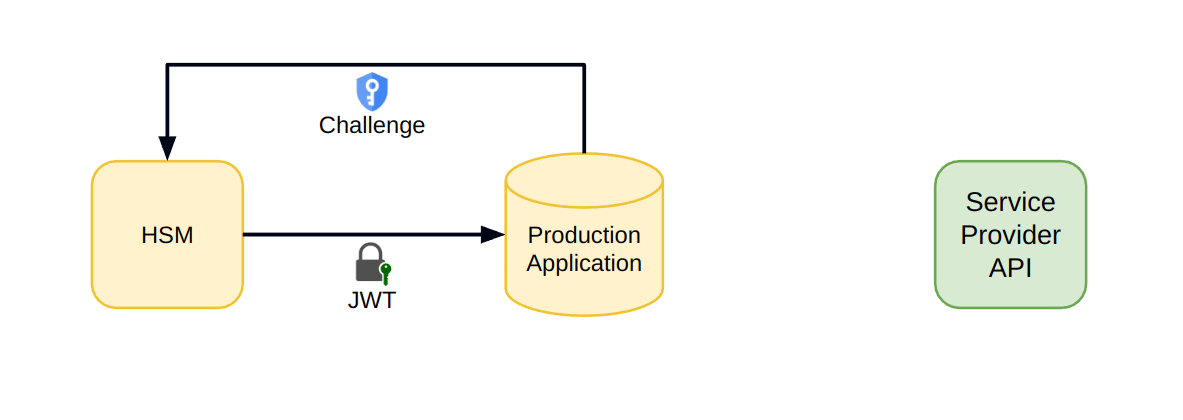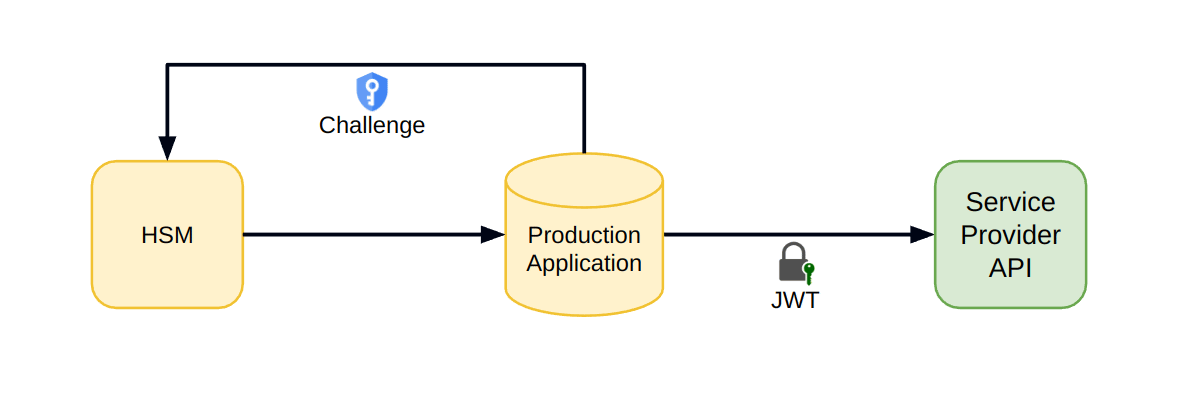
- Instead of production, the HSM will generate the key pair and expose the public key for usage.
- Production will have access to the key, and as before, it can expose it for us.
- We'll upload the public key to the Service Provider.
- Later, when we want to access the Service Provider, we'll issue a challenge to the HSM.
- The HSM will generate a signed JWT to our production runtime.
- From there, our production runtime will use that JWT in the requests sent to the Service Provider.
With that, we've eliminated the last vulnerability. Not even production has access to the sensitive credential used to authorize to the Service Provider.
Conclusions
- Environment Variables actually create new attack vectors, our sensitive credentials should never be anywhere near environment variables.
- Using a Key Management Service with encrypted credentials secured in source code is the best client-side solution. It is the best we can do as long as the Service Provider doesn't offer anything better.
- If we are the Service Provider, then we need to provide BYOK and we have to support asymmetric keys for our users.
Lastly, it's worth saying a couple words about choosing the appropriate strategy. It's probably not a good idea to just arbitrarily just take whatever has been said in this article and attempt to directly implement it without comprehensive understanding. While each of these provides potential improvements, it's important to understand your threat model. Where are your attackers actually coming from? And what strategies will they employ to compromise your service and sensitive data? Take the opportunity to be able to say explicitly this X is a concrete problem that we have and it is solved with this explicit strategy Y. If you just go and implement these without consciously thinking them through, you may miss key components to getting the strategy correct, and instead of implementing a shiny new security strategy, you are actually enabling additional credential exposure, or worse, compromise.
API Security is not something you get right in a one or two week sprint, it takes deliberate attention, it's not some 20 minute adventure.
