

For help understanding this article or how you can implement auth and similar security architectures in your services, feel free to reach out to me via the community server.
🚨 AWS us-east-1 is down!
One of the most massive AWS incidents transpired on October 20th. The long story short is that the DNS for DynamoDB was impacted for us-east-1, which created a health event for the entire region. It's the worst incident we've seen in a decade. Disney+, Lyft, McDonald's, New York Times, Reddit, and the list goes on were lining up to claim their share too of the spotlight. And we've been watching because our product is part of our customers critical infrastructure. This one graph of the event says it all:
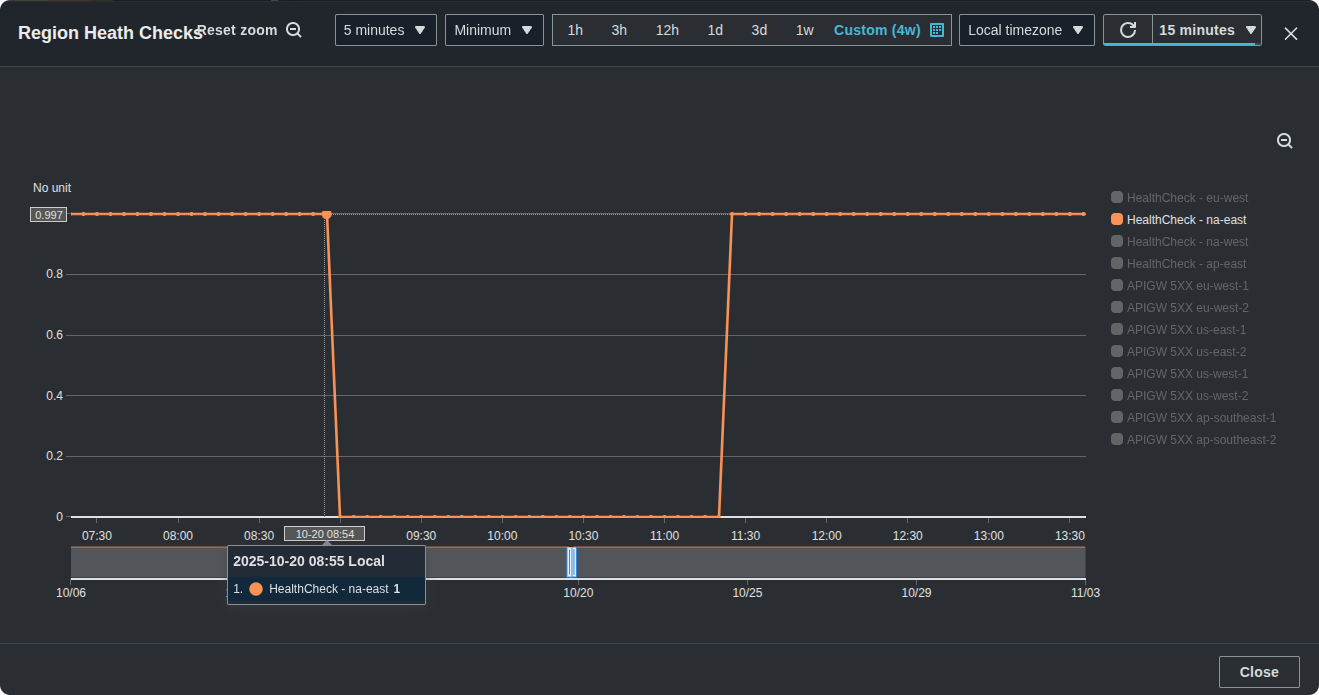
The AWS post-incident report indicates that at 7:48 PM UTC DynamoDB had "increased error rates". But this article isn't about AWS, and instead I want to share how exactly we were still up when when AWS was down.
Now you might be thinking: why are you running infra in us-east-1?
And it's true, almost no one should be using us-east-1, unless, well, of course, you are us. And that's because we end up running our infrastructure where our customers are. In theory, practice and theory are the same, but in practice they differ. And if our (or your) customers chose us-east-1 in AWS, then realistically, that means you are also choosing us-east-1 😅.
During this time, us-east-1 was offline, and while we only run a limited amount of infrastructure in the region, we have to run it there because we have customers who want it there. And even without a direct dependency on us-east-1, there are critical services in AWS — CloudFront, Certificate Manager, Lambda@Edge, and IAM — that all have their control planes in that region. Attempting to create distributions or roles at that time were also met with significant issues.
Since there are plenty of articles in the wild talking about what actually happened, why it happened, and why it will continue to happen, I don't need to go into it here. Instead, I'm going to share a dive about exactly what we've built to avoid these exact issues, and what you can do for your applications and platforms as well. In this article, I'll review how we maintain a high SLI to match our SLA reliability commitment even when the infrastructure and services we use don't.
📖 What is reliability?
Before I get to the part where I share how we built one of the most reliable auth solutions available. I want to define reliability. And for us, that's an SLA of five nines. I think that's so extraordinary that the question I want you to keep in mind through this article is: is that actually possible? Is it really achievable to have a service with a five nines SLA? When I say five nines, I mean that 99.999% of the time, our service is up and running as expected by our customers. And to put this into perspective, the red, in the sea of blue, represents just how much time we can be down.

And if you can't see it, it's hiding inside this black dot. It amounts to just five minutes and 15 seconds per year. This pretty much means we have to be up all the time, providing responses and functionality exactly as our customers expect.

🤔 But why?
To put it into perspective, it's important to share for a moment, the specific challenges that we face, why we built what we built, and of course why that's relevant. To do that, I need to include some details about what we're building — what Authress actually does. Authress provides login and access control for the software applications that you write — It generates JWTs for your applications. This means:
- User authentication and authorization
- User identities
- Granular role and resource-based authorization (ReBAC, ABAC, TBAC, RBAC, etc...)
- API keys for your technical customers to interact with your own APIs
- Machine to machine authentication, or services — if you have a microservice architecture.
- Audit trails to track the permission changes within your services or expose this to your customers.
And there are of course many more components, that help complete full auth-platform, but they aren't totally relevant to this article, so I'm going to skip over them.
With that, you may already start to be able to see why uptime is so critical for us. We're on the critical path for our customers. It's not inherently true for every single platform, but it is for us. So if our solution is down, then our customer applications are down as well.
If we put the reliability part in the back corner for one second and just think about the features, we can theorize about a potential initial architecture. That is, an architecture that just focuses on the features, how might you build this out as simple as possible? I want to do this, so I can help explain all the issues that we would face with the simple solution.
Maybe you've got a single region, and in that region you have some sort of HTTP router that handles requests and they forward to some compute, serverless, container, or virtual machine, or, and I'm very sorry for the scenario — if you have to use bare metal. Lastly, you're interacting with some database, NoSQL, SQL, or something else, file storage, and maybe there's some async components.
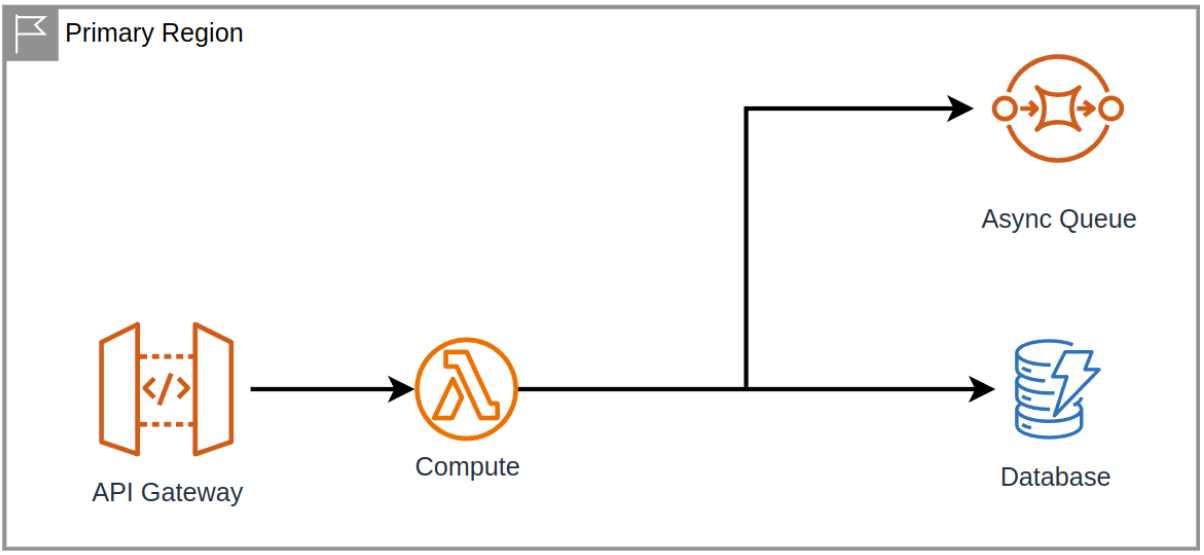
If you take a look at this, it's probably obvious to you (and everyone else) that there is no way it is going to meet our reliability needs. But we have to ask, just exactly how often will there actually be a problem with this architecture? Just building out complexity doesn't directly increase reliability, we need to focus on why this architecture would fail. For us, we use AWS, so I look to the Amazon CTO for guidance, and he's famously quoted as saying, Everything fails all the time.
And AWS's own services are no exception to this. Over the last decade, we've seen numerous incidents:
- 2014 - Ireland (Partial) - Hardware - Transformer failed - EC2, EBS, and RDS
- 2016 - Sydney (Partial) - Severe Weather - Power Loss - All Services
- 2017 - All Regions - Human error - S3 critical servers deleted - S3
- 2018 - Seoul Region - Human error - DNS resolvers impacted - EC2
- 2021 - Virginia - Traffic Scaling - Network Control Plane outage - All Services
- 2021 - California - Traffic Scaling - Network Control Plane outage - All Services
- 2021 - Frankfurt (Partial) - Fire - Fire Suppression System issues - All Services
- 2023 - Virginia - Kinesis issues - Scheduling Lambda Invocations impact - Lambda
- 2023 - Virginia - Networking issues - Operational issue - Lambda, Fargate, API Gateway…
- 2023 - Oregon (Partial) - Error rates - Dynamodb + 48 services
- 2024 - Singapore (Partial) - EC2 Autoscaling - EC2
- 2024 - Virginia (Partial) - Describe API Failures ECS - ECS + 4 services
- 2024 - Brazil - ISP issues - CloudFront connectivity - CloudFront
- 2024 - Global - Network connectivity - STS Service
- 2024 - Virginia - Message size overflow - Kinesis down - Lambda, S3, ECS, CloudWatch, Redshift
- 2025 - Virginia - Dynamo DB DNS - DynamoDB down - All Services
- 2026 - Ireland - Networking Change Delays - Elevated latencies - 22 Services
(Edit: And since this article was published AWS started keeping track in their own list and the AWS Health Events Dashboard)
And any one of these would have caused major problems for us and therefore our customers. And the frequency of incident is actually increasing in time. This shouldn't be a surprise, right? Cloud adoption is increasing over time. The number of services AWS is offering is also increasing. But how impactful are these events? Would single one of them have been a problem for us to actually reach our SLA promise? What would happen if we just trusted AWS and used that to pass through our commitments? Would it be sufficient to achieve 99.999% SLA uptime? Well, let's take a look.
🕰️ AWS SLA Commitments
The AWS Lambda SLA is below 5 nines

The API Gateway SLA is below 5 nines
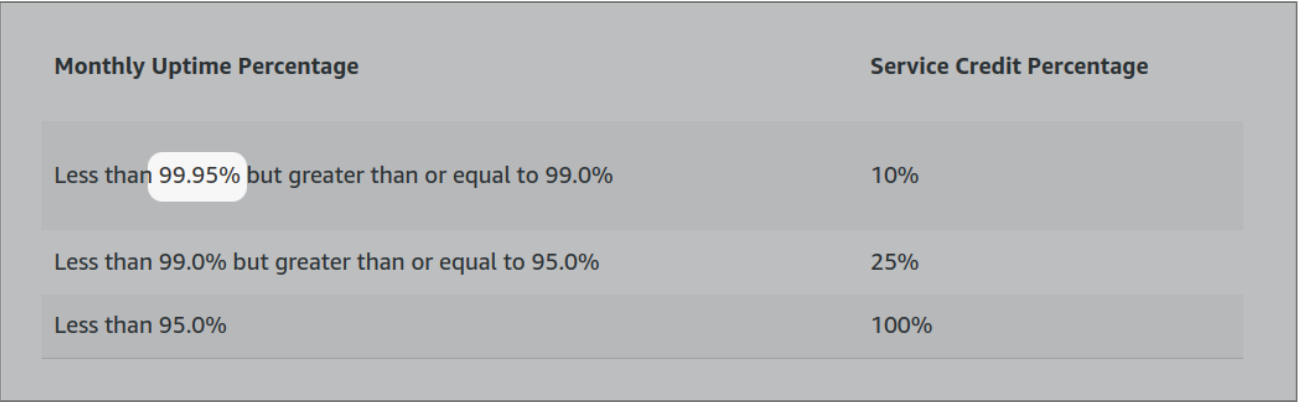
The AWS SQS SLA is below 5 nines
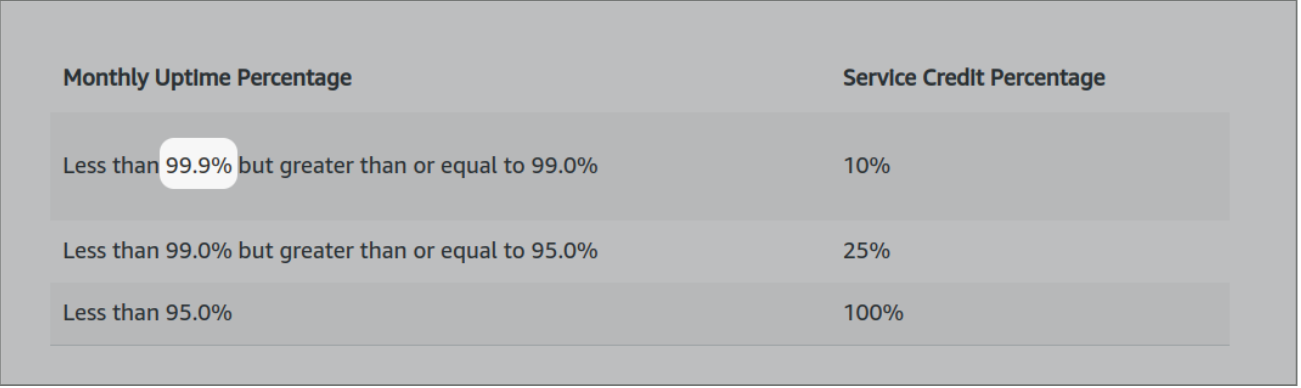
Okay, so when it comes to trusting AWS SLAs, it isn't sufficient. At. All.
We can't just use the components that are offered by AWS, and go from there. We fundamentally need to do something more than that. So the question becomes, what exactly must a dependency's reliability be in order for us to utilize it? To answer that question, it's time for a math lesson. Or more specifically, everyone's favorite topic, probabilities.
Let's quickly get through this torture exercise. Fundamentally, you have endpoints in your service, and you get in an HTTP request, and it interacts with some third-party component or API, and then you write the result to a database. For us, this could be an integration such as logging in with Google or with Okta for our customers' enterprise customers.
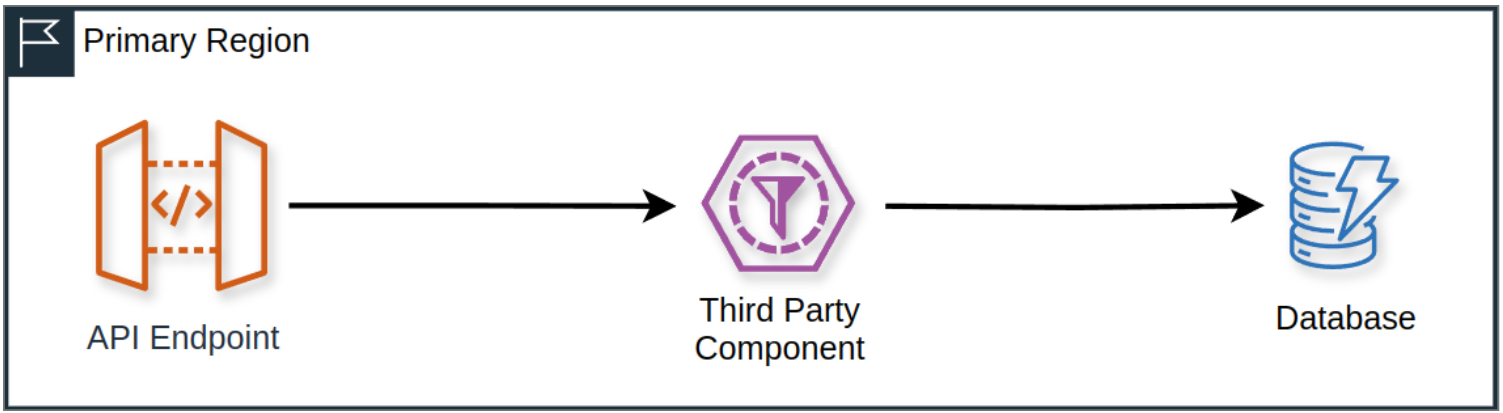
💻 Calculating the allowed failure rate
So if we want to meet a 5-nines reliability promise, how unreliable could this third-party component actually be? What happens if this component out of the box is only 90% reliable? We'll design a strategy for getting around that.
Uptime is a product of all of the individual probabilities:
For the sake of this example, we'll just assume that every other component in our architecture is 100% reliable — That's every line of code, no bugs ever written in our library dependencies, or transitive library dependencies, or the dependencies' dependencies' dependencies, and everything always works exactly as we expect.
So we can actually rewrite our uptime promise as a result of the failure rate of that third-party component.
And the only way that we can actually increase the success rate of the uptime based off of failures is to retry. And so we can multiply out the third-party failure rate and retry multiple times.
Logically that makes a lot of sense. When a component fails, if you retry again, and again, the likelihood it will be down every single time approaches zero. And we can generate a really nasty equation from this to actually determine how many exact times do we need to retry.
How many exactly can it? Rather than guessing whether or not we should retry four times or five times, or put it in a while(true) loop, we can figure it out exactly. So we take this equation and extend it out a little bit. Plugging in our 90% reliable third-party component:
We find that our retry count actually must be greater than or equal to five. We can see that this adds up to our uptime expectation:
Is this the end of the story? Just retry a bunch of times and you're good? Well, not exactly. Remember this equation?
We do really need to consider every single component that we utilize. And specifically when it comes to the third-party component, we had to execute it by utilizing a retry handler. So we need to consider the addition of the retry handler into our equation. Going back to the initial architecture, instead of what we had before, when there's a failure in that third-party component, now we will automatically execute some sort of asynchronous retries or in-process retries. And every time that third-party component fails, we execute the retry handler and retry again.
This means we need to consider the reliability of that retry handler.
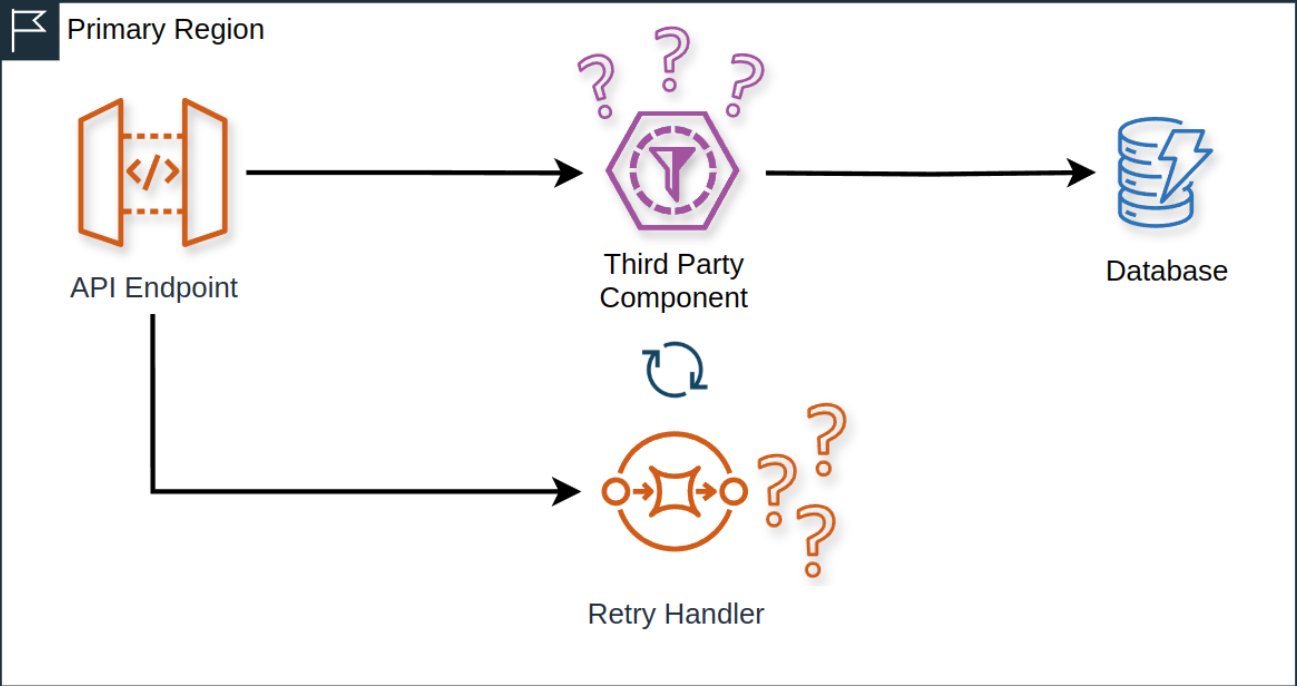
Let's assume we have a really reliable retry handler and that it's even more reliable than our service. I think that's reasonable, and actually required. A retry handler that is less reliable than our stated SLA by default is just as faulty as the third-party component.
Let's consider one with five and a half nines — that's half a nine more reliable than our own SLA.
But how reliable does it really need to be? Well, we can pull in our original equation and realize that our total uptime is the unreliability or the reliability of the third-party component multiplied by the reliability of our retry handler.
From here, we add in the retries to figure out what the result should be:
We have a reliable retry handler, but it's not perfect. And with a retry handler that has reliability of five and a half nines, we can retry a maximum two times. Because remember, it has to be reliable every single time we utilize it, as it is a component which can also fail. Which means left with this equation:
I don't think comes as a surprise to anyone that in fact five is greater than two. What is the implication here?
The number of retries required for that unreliable third-party component to be utilized by us exceeds the number of retries actually allowed by our retry handler.
That's a failure, the retry handler can only retry twice before itself violates our SLA, but we need to retry five times in order to raise the third-party component reliably up. We can actually figure out what the minimum reliability of a third-party component is allowed to be, when using our retry handler:
Which in turn validates that it's actually impossible for us to utilize that component. 99.7%. 99.7% is the minimum allowed reliability for any third-party component in order for us to meet our required 5-nines SLA. This third-party component is so unreliable (~90%), that even using a highly reliable retry handler, we still can't make it reliable enough without the retry handler itself compromising our SLA. We fundamentally need to consider this constraint, when we're building out our architecture.
That means we drop this third-party component. Done.
And then, let's assume we get rid of every flaky component, everything that don't have a high enough reliability for us. At this point, it's good to think, is this sufficient to achieve our 5-nines SLA? Well, it isn't just third-party components we have to be concerned about. We also have to be worried about those AWs infrastructure failures.
🌩️ Infrastructure Failures
So let's flashback to our initial architecture again:
We can have issues at the database layer, right? There could be any number of problems here. Maybe it's returning 500s, there are some slow queries, maybe things are timing out. Or there could be a problem with our compute. Maybe it's not scaling up fast enough. We're not getting new infrastructure resources. Sometimes, even AWS is out of bare metal machines when you don't reserve them, request them get them on demand, and the list go on.
Additionally, there could also be some sort of network issue, where requests aren't making it through to us or even throw a DNS resolution error on a request from our users.
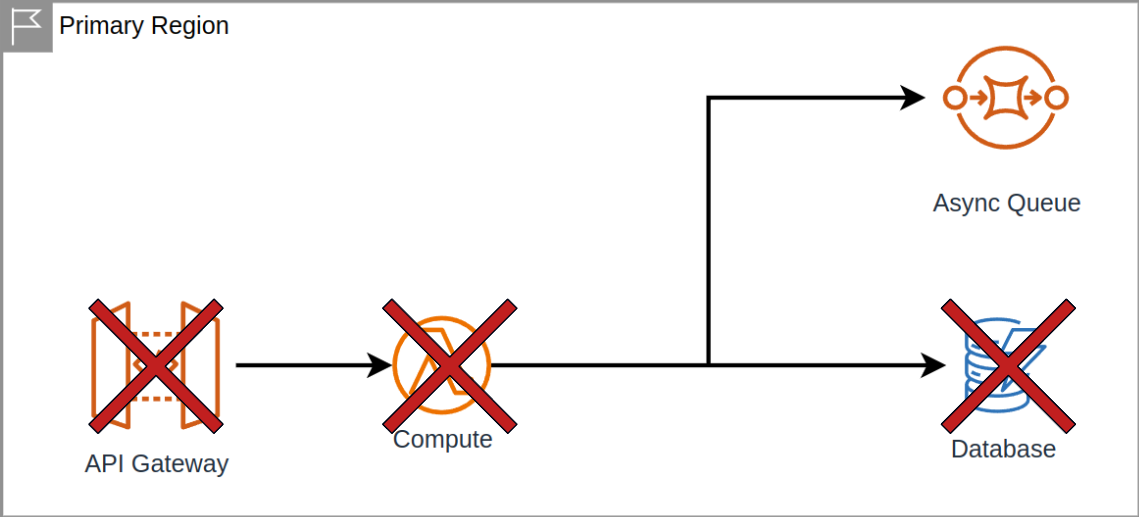
In many of these cases, I think the answer is obvious. We just have to declare the whole region as down. And you are probably thinking, well, this is where we failover to somewhere else. No surprise, yeah, this is exactly what we do:
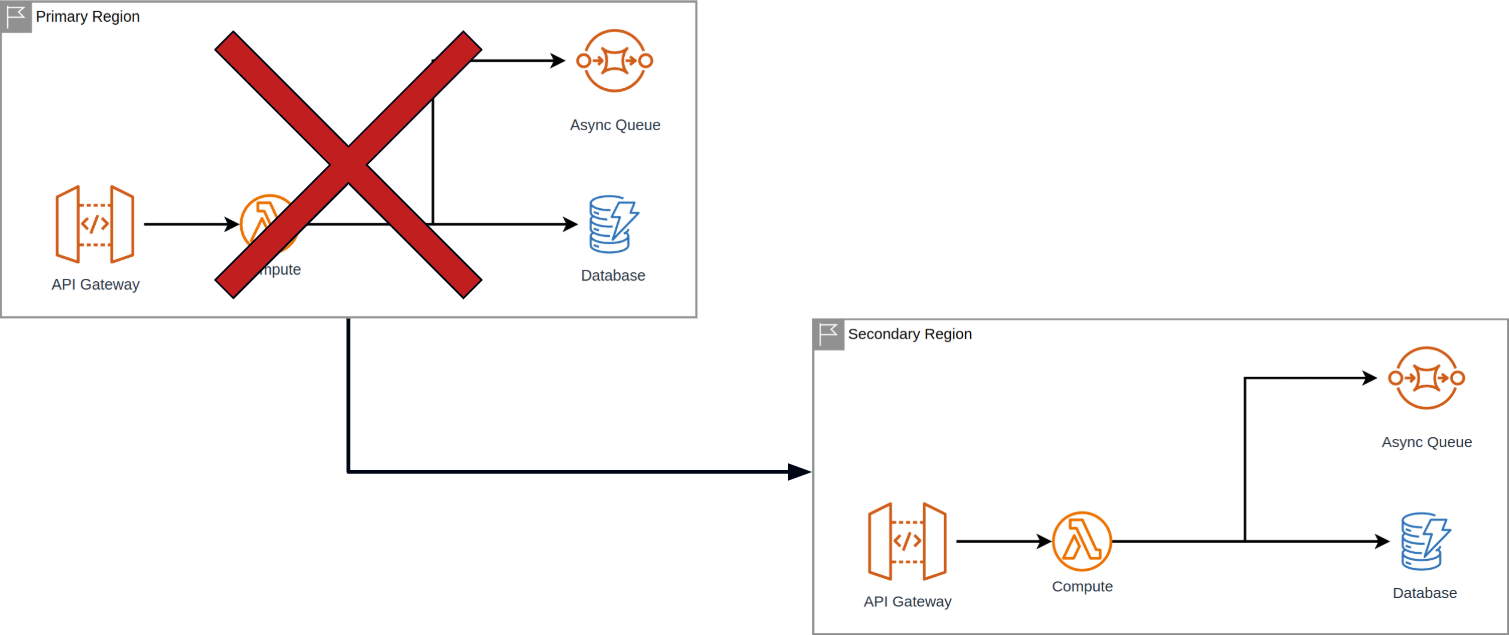
However, this means we have to have all the data and all the infrastructure components duplicated to another region in order to do this. And since Authress has six primary regions around the world, that also means we need multiple backup regions to be able to support the strategy. But this comes with significant wasted resources and wasted compute that we're not even getting to use. Costly! But I'll get to that later.
Knowing a redundant architecture is required is a great first step, but that leaves us having to solve for: how do we actually make the failover happen in practice?
🚧 The Failover Routing Strategy
Simply put — our strategy is to utilize DNS dynamic routing. This means requests come into our DNS and it automatically selects between one of two target regions, the primary region that we're utilizing or the failover region in case there's an issue. The critical component of the infrastructure is to switch regions during an incident:
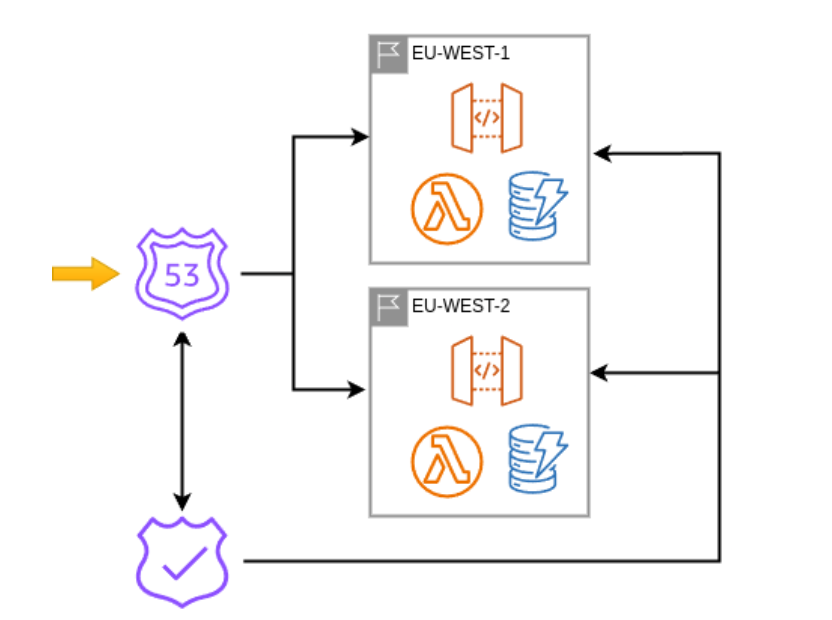
In our case, when using AWS, this means using the Route 53 health checks and the Route 53 failover routing policy.
We know how we're gonna do it, but the long pole in the tent is actually knowing that there is even a problem in the first place. A partial answer is to say Have a health check, so of course there is health check here. But the full answer is: have a health check that validates both of the regions, checking if the region is up, or is there an incident? And if it is, reports the results to the DNS router.
We could be utilizing the default provided handler from AWS Route 53 or a third-party component which pings our website, but that's not accurate enough from a standpoint of correctly and knowing for certain that our services are in fact down.
It would be devastating for us to fail over when a secondary region is having worse problems than our primary region. Or what if there's an issue with with network traffic. We wouldn't know if that's an issue of communication between AWS's infrastructure services, or an issue with the default Route 53 health check endpoint, or some entangled problem with how those specifically interact with our code that we're actually utilizing. So it became a requirement to built something ourselves, custom, to actually execute exactly what we need to check.
Here is a representation of what we're doing. It's not exactly what we are doing, but it's close enough to be useful. Health check request come in from the Route 53 Health Check. They call into our APIGW or Load Balancer as a router. The requests are passed to our compute which can interact and validate logic, code, access, and data in the database:
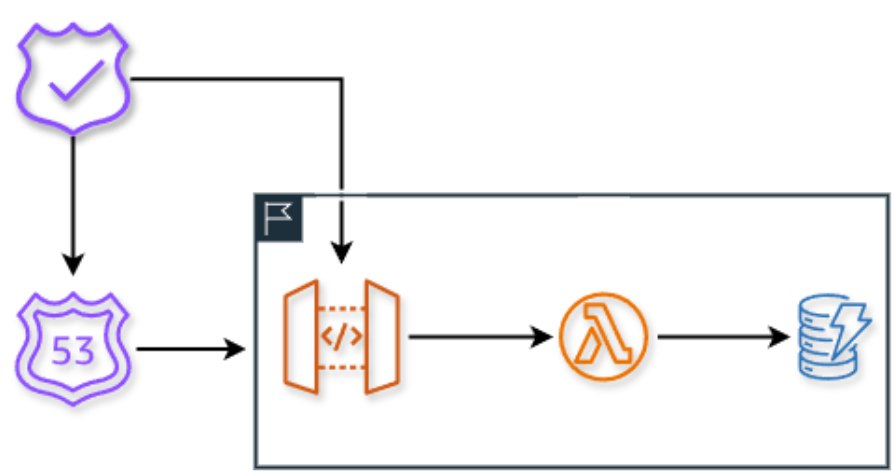
The health check executes this code on request that allows us to validate if the region is in fact healthy:
import Authorizer from './authorizer.js';
import ModelValidator from './modelValidator.js';
async healthCheck(request) {
await profiler.start();
const dynamoDbCheck = accountDatabase.getDefaultAccount();
const indexerCheck = indexer.authorizationCheck('HealthCheck');
const sqsValidation = sqsClient.queue('LiveCheck');
const authorizer = Authorizer.validate();
const modelValidation = ModelValidator.validate();
try {
await Promise.all([
dynamoDbCheck, indexerCheck, sqsValidation,
authorizer, modelValidation ]);
} catch (error) {
logger.log('HealthCheck Failed', error);
return { statusCode: 503 };
}
await profiler.end();
return { statusCode: 200 };
}
- We start a profiler to know how long our requests are taking.
- Then we interact with our databases, as well as validate some secondary components, such as SQS. While issues with secondary components may not always be a reason to failover, they can cause impacts to response time, and those indicators can be used to predict incoming incidents.
- From there, we check whether or not the most critical business logic is working correctly. In our case, that's interactions with DynamoDB as well as core authorizer logic. Compared to a simple unit test, this accounts for corruption in a deployment package, as well instances where some subtle differences between regions interact with our code base. We can catch those sorts of problems here, and know that the primary region that we're utilizing, one of the six, is having a problem and automatically update the DNS based on this.
- When we're done, we return success or failure so the health check can track changes.
🌿 Improving the Failover Strategy
And we don't stop here with our infrastructure failover however. With the current strategy, it's good, in some cases, even sufficient. But it isn't that great. For starters, we have to completely failover. If there's just one component that's problematic, we can't just swap that one out easily, it's all or nothing with the Route 53 health check. So when possible, we push for an edge-optimized architecture. In AWS, this means utilizing AWS CloudFront with AWS Lambda@Edge for compute. This not only helps reduce latency for our customers and their end users depending where they are around the world, as a secondary benefit, fundamentally, it is an improved failover strategy.
And that looks like this:
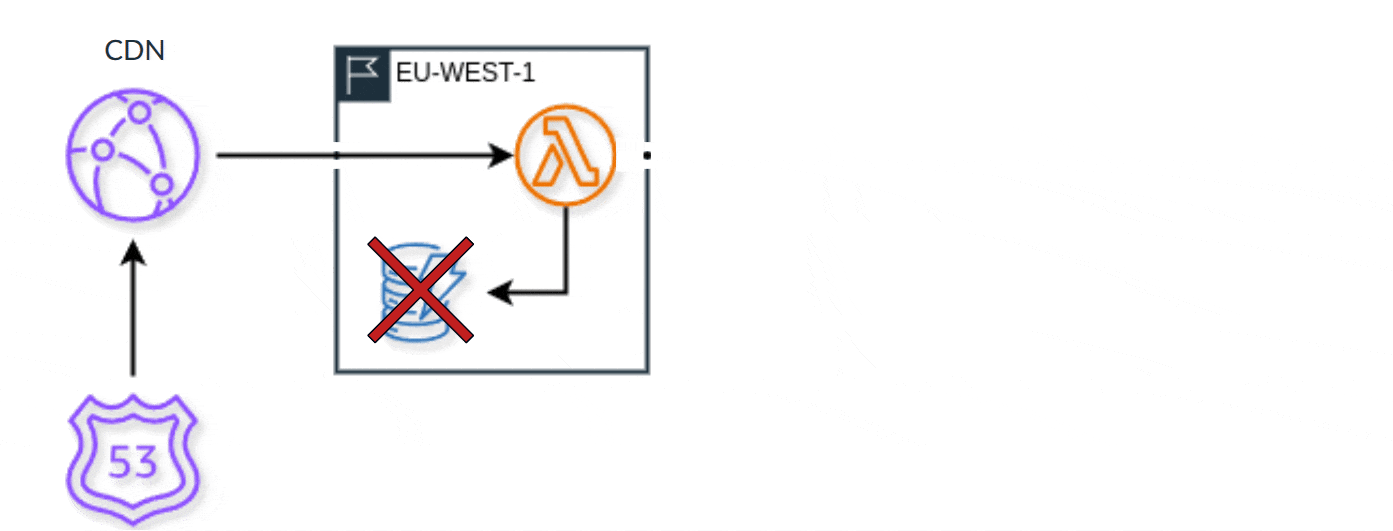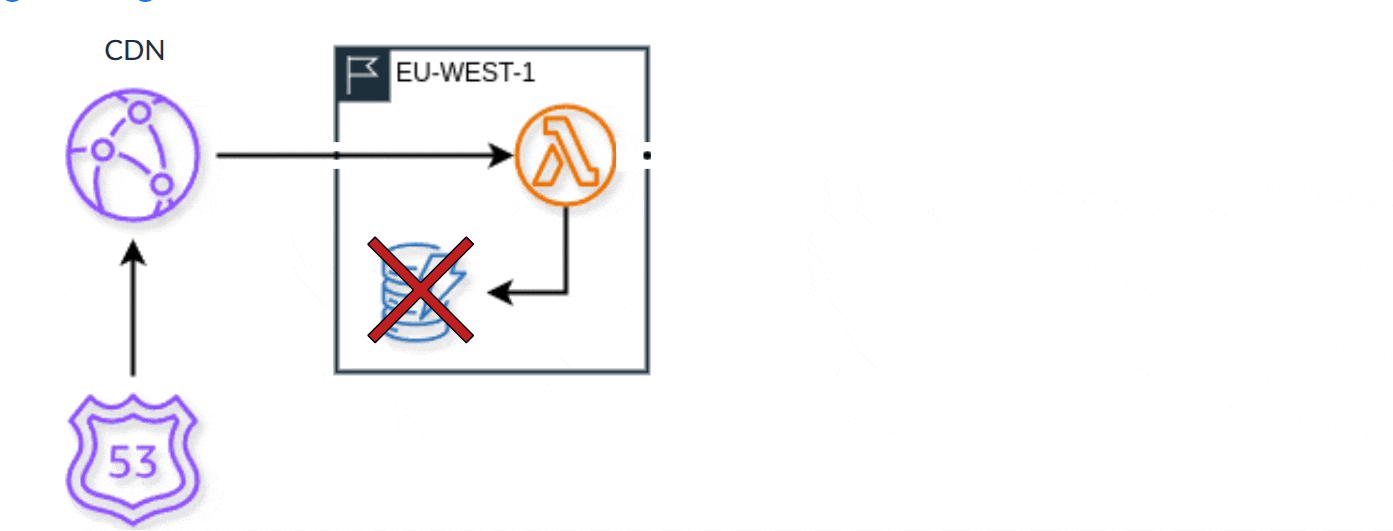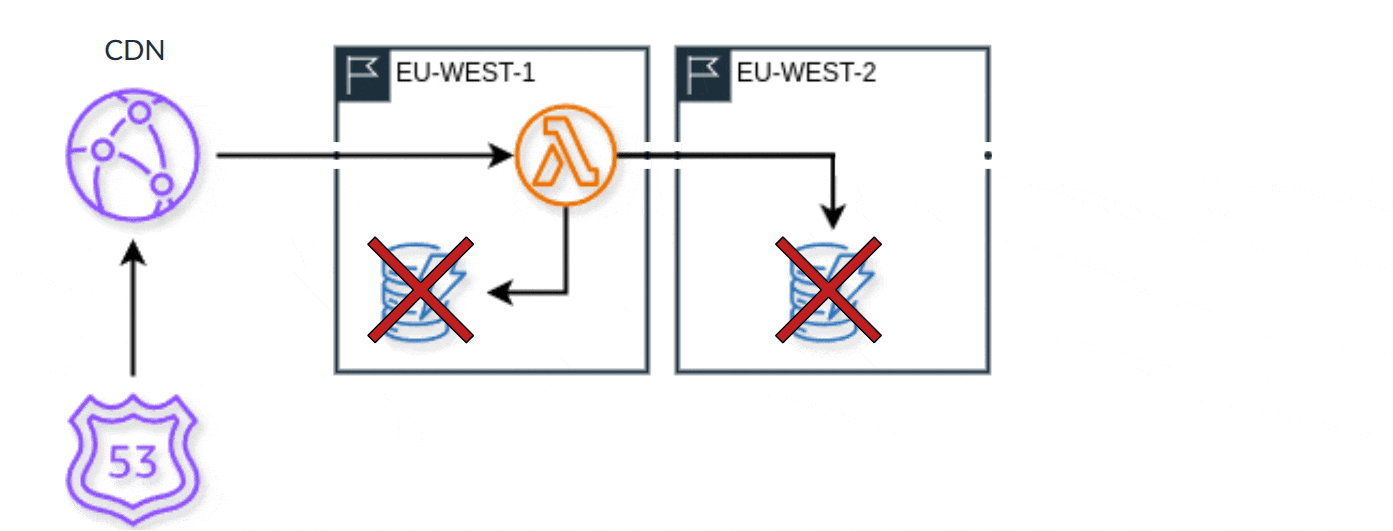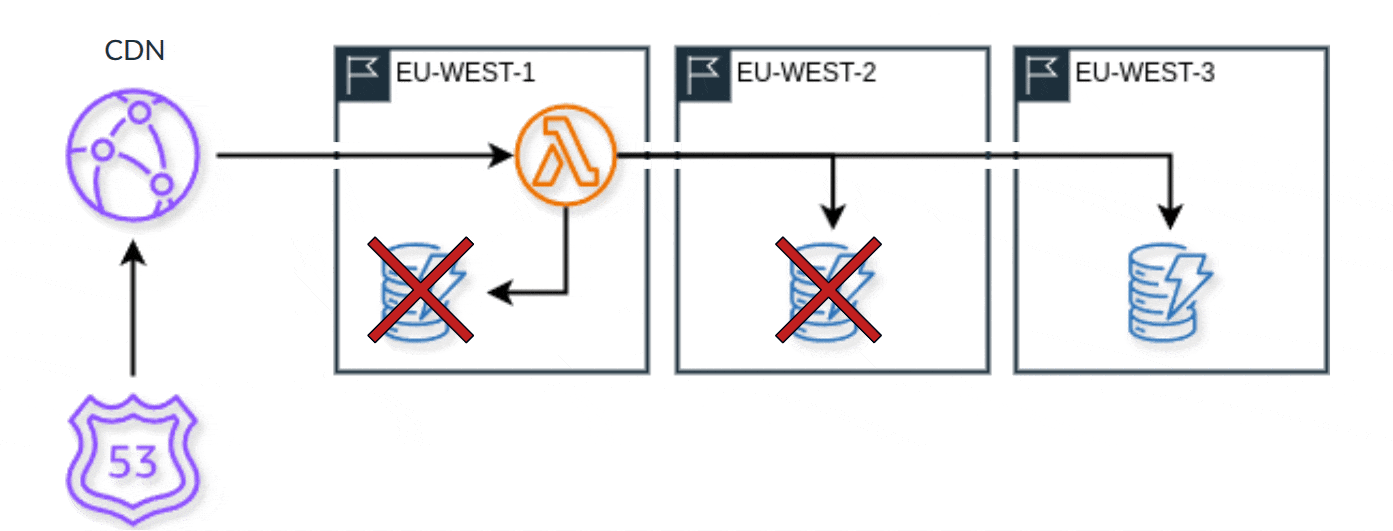
Using CloudFront gives us a highly reliable CDN, which routes requests to the locally available compute region. From there, we can interact with the local database. When our database in that region experiences a health incident, we automatically failover, and check the database in a second adjacent region. And when there's a problem there as well, we do it again to a third region. We can do that because when utilizing DynamoDB we have Global Tables configured for authorization configuration. In places where we don't need the data duplicated, we just interact with the table in a different region without replication.
After a third region with an issue, we stop.
And maybe you're asking why three and not four or five or six? Aren't you glad we did the probabilities exercise earlier? Now you can actually figure out why it's three here. But, I'll leave that math as an exercise for you.
As a quick recap, this handles the problems with at the infrastructure level and with third-party components. And if we solve those, is that sufficient for us to achieve our goal the 5-nines SLA?
For us the answer is No, and you might have guessed, if you peaked at the scrollbar or table contents that there are still quite some additional components integrated into our solution. One of them is knowing that at some point, there's going to be a bug in our code, unfortunately.
💻 Application level failures
And that bug will get committed to production, which means we're going to end up with an application failure. It should be obvious that it isn't achievable to write completely bug-free code. Maybe there is someone out there that thinks that, and maybe even that's you, and I believe you that you believe that. However, I know it's not me, and realistically, I don't want to sit around and pray that it's also my fellow team members. The risk is too high, because in the case something does get into production, that means it can impact some of our customers. So instead, let's assume that will happen and design a strategy around it.
So when it does happen, we of course have to trigger our incident response. For us, we send out an email, we post a message on our community and internal communication workspaces, and start an on-call alert. The technology here isn't so relevant, but tools like AWS SES, SQS, SNS, Discord, and emails are involved.
Incidents wake an engineer up, so someone can start to take look at the incident, and most likely the code.
But by the time they even respond to the alert, let alone actually investigate and fix the cause of the incident, we would long violated our SLA. So an alert is not sufficient for us. We need to also implement automation to automatically remediate any of these problems. Now, I'm sure you're thinking, yeah, okay, test automation. You might even be thinking about an LLM agent that can automatically create PRs. (Side note: LLM code generation, doesn't actually work for us, and I'll get to that a little further down) Instead, we have to rely on having sufficient testing in place. And yes, of course we do. We test before deployment. There is no better time to test.
This seems simple and an obvious answer, and I hope that for anyone reading this article it is. Untested code never goes to production. Every line of code is completely tested before it is merged to production, even if it is enabled on some flag. Untested code is never released, it is far too dangerous. Untested code never makes it to production behind some magic flag. Abusing feature flags to make that happen could not be a worse decision for us. And that's because we can need to be as confident as possible before those changes actually get out in front of our customers. The result is — we don't focus on test coverage percentage, but rather test value. That is, which areas provide most value, that are most risky, that we care about being the most reliable for our customers. Those are the ones we focus on testing.
Root Cause Analysis (RCA)
Every incident could have been prevented if we just had one more test. The trick though is actually having that right test, before the incident.
And in reality, that's not actually possible. Having every right test for a service that is constantly changing, while new features are being added, is just unmaintainable. Every additional test we write increases the maintenance burden of our service. Attempting to achieve 100% complete test coverage would require an infinite amount of time. This is known as the Pareto Principle, more commonly the 80-20 rule. If it takes 20% of the time to deliver 80% of the tests, it takes an infinite amount of time to achieve all the tests, and that assumes that the source code isn't changing.
The result is we'll never be able to catch everything. So we can't just optimize for prevention. We also need to optimize for recovery. This conclusion for us means also implementing tests against our deployed production code. One example of this are validation tests.
📋 Validation Tests
A validation test is where you have some data in one format and data in another format and you use those two different formats to ensure referential consistency. (Side note: There are many different kinds of tests, and I do a deep dive in the different types of tests and how they're relevant in building secure and reliable systems). One concrete example could be you have a request that comes in, you end up logging the request data and the response, then you can compare that logged data to what's actually saved in your database.
In our scenario, which focuses on the authorization and permissions enforcement checks, we have multiple databases with similar data. In one case, there's the storage of permissions as well as the storage of the expected checks and the audit trail tracking the creation of those permissions. So we actually have multiple opportunities to compare the data between our databases asynchronously outside of customer critical path usage.
Running the Validation
On a schedule, via an AWS CloudWatch Scheduled Rule, we load the data from our different databases and we compare them against each other to make sure it is consistent. If there is a problem, then if this fires off an incident before any of our customers notice, so that we can actually go in and check what's going on.
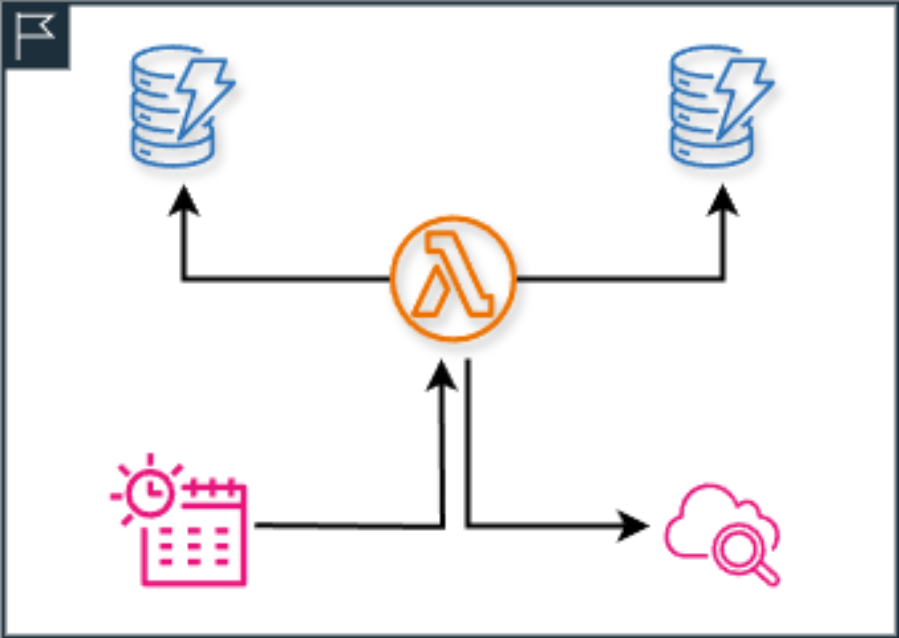
This sounds bad on the surface that it could ever happen. But the reality of the situation is that a discrepancy can show up as a result of any number of mechanisms. For instance, the infrastructure from AWS could have corrupted one of the database shards and what is written to the databases is inconsistent. We know that this can happen as there is no 100% guarantee on database durability, even from AWS. AWS does not guarantee Database Durability, are you assuming they do, because we don't! So actually reading the data back and verifying its internal consistency is something that we must do.
While it might not seem that this could reduce the probability of there being an incident. Consider that a requested user permission check whose result doesn't match our customer's expectation is an incident. It might not always be one that anyone identifies or even becomes aware of, but it nonetheless a problem, just like a publicly exposed S3 is technically an issue, even if no one has exfiltrated the data yet, it doesn't mean the bucket isn'is sufficiently secured.
🎯 Incident Impact
There are two parts to the actual risk of an incident. The probability and the impact. Everything in this article I've discuss until now talks about reducing the probability of an incident, that is — the likelihood of it happening. But since we know that we can't avoid ever having an incident, we also have to reduce the impact when it happens.
One way we do that is by utilizing an incremental rollout. Hopefully everyone knows what incremental rollout is, so I'll instead jump straight into how we accomplish it utilizing AWS. And for that we focus again on our solution integrating with CloudFront and our edge architecture.
The solution for us is what I call Customer Deployment Buckets. We bucket individual customers into separate buckets and then deploy to each of the buckets sequentially. If the deployment rolls out without a problem, and it's all green, that is everything works correctly, then we go on to the second bucket and then deploy our code to there, and then the third bucket, and so on and so forth until every single customer has the new version.
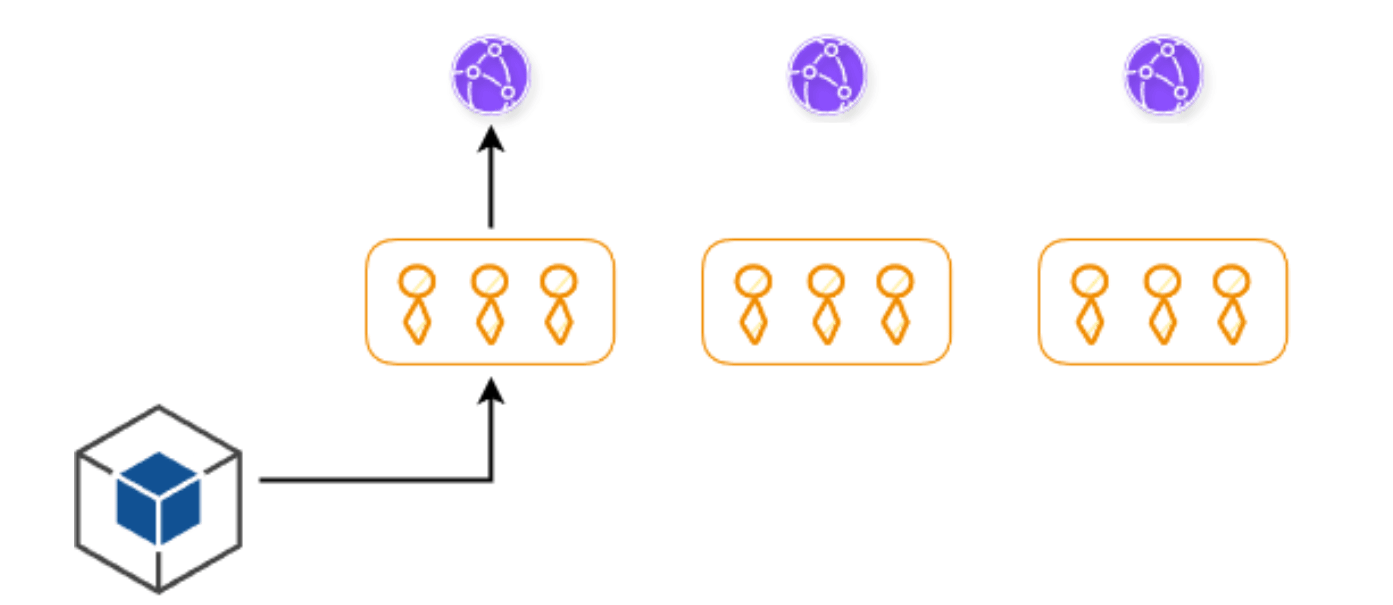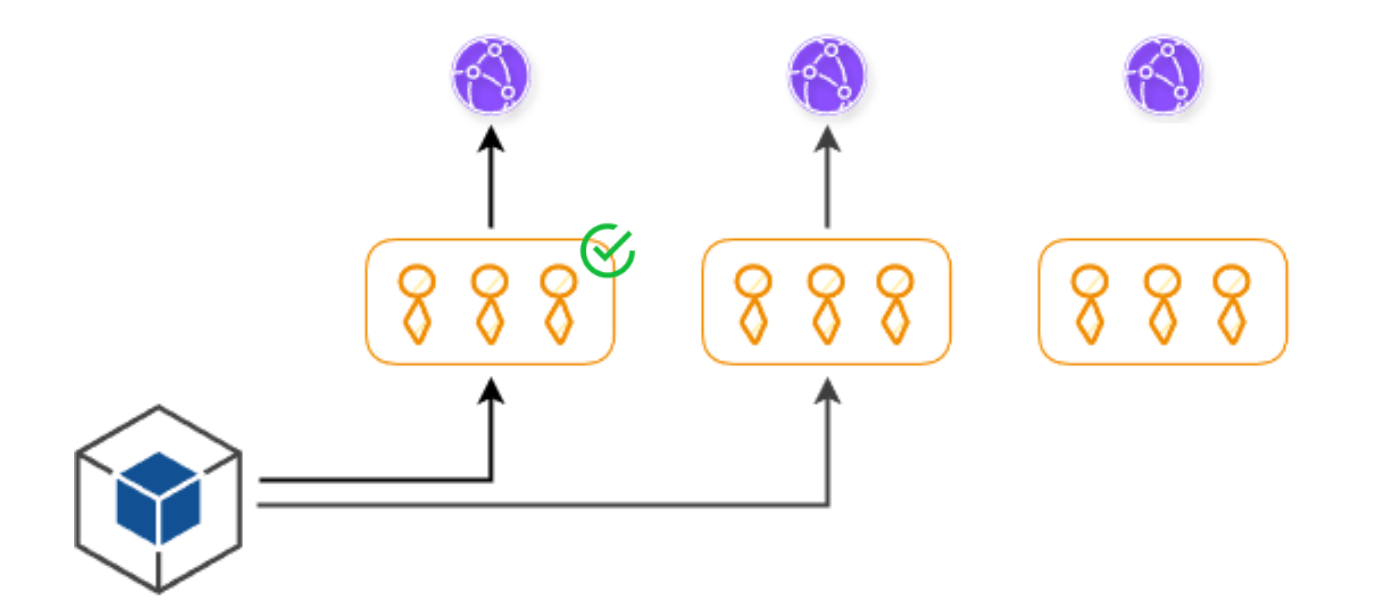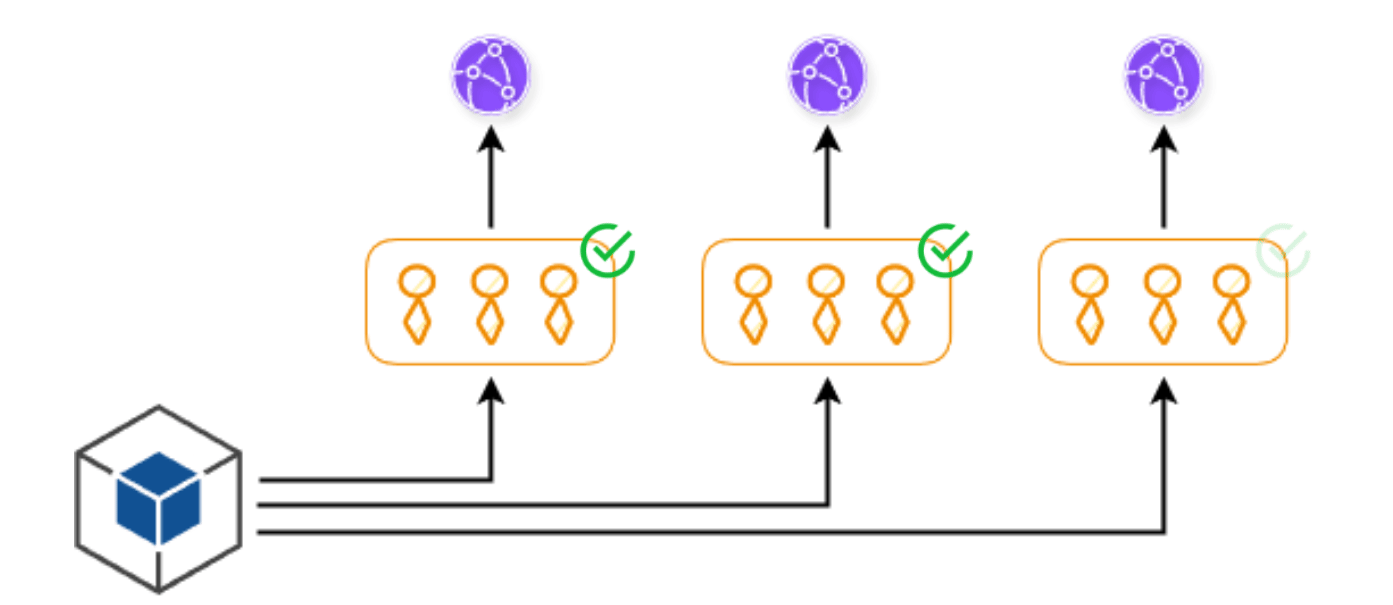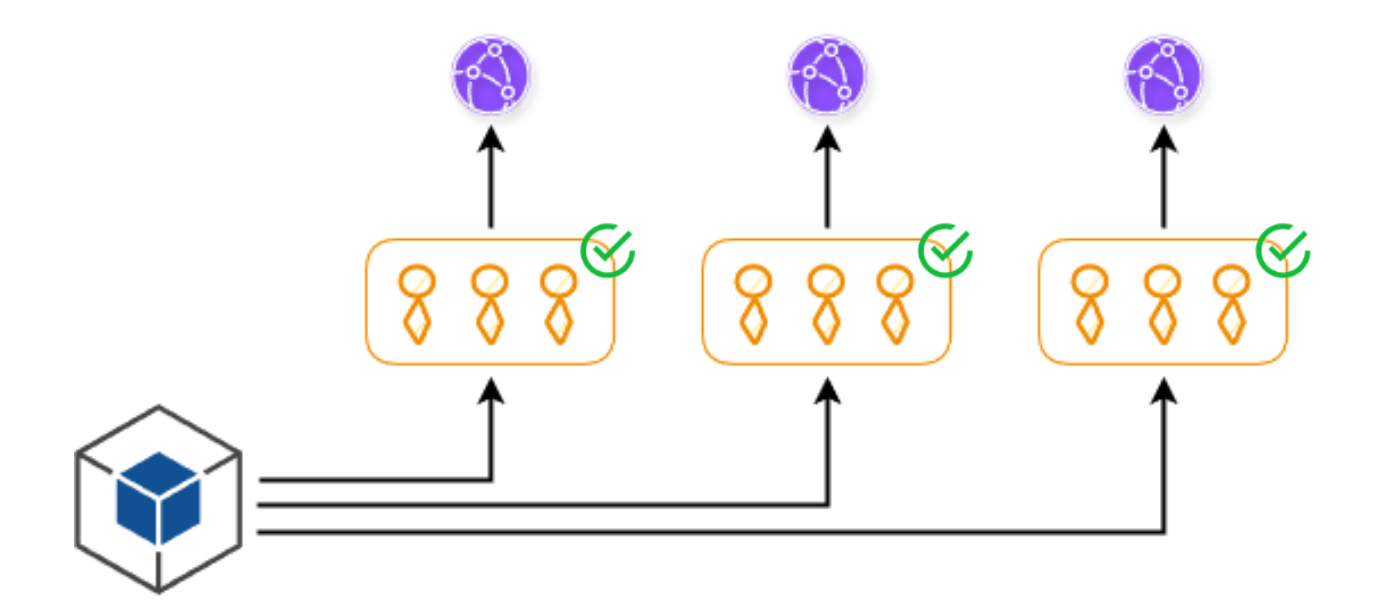
If there is an issue, we stop the rollout and we go and investigate what's actually going on. While we can't prevent the issue from happening to the earlier buckets, we are able to stop that issue from propagating to more customers, having an impact on everyone, and thus reduce the impact of the incident.
As I mentioned before the biggest recurring issue isn't executing an operations process during an incident, it's identifying there is a real incident in the first place. So, How do we actually know that there's an issue?
If it was an easy problem to solve, you would have written a unit task or integration test or service level test and thus already discovered it, right? So adding tests can't, by design, help us. Maybe there's an issue with the deployment itself or during infrastructure creation, but likely that's not what's happening.
Now, I know you're thinking, When is he going to get to AI?
Whether or not we'll ever truly have AI is a separate <rant /> that I won't get into here, so this is the only section on it, I promise. What we actually do is better called anomaly detection. Historically anomaly detection, was what AI always meant, true AI, rather than an LLM or agent in any way.
🔎 AI: Anomaly Detection
This is a graph of our detection analysis:
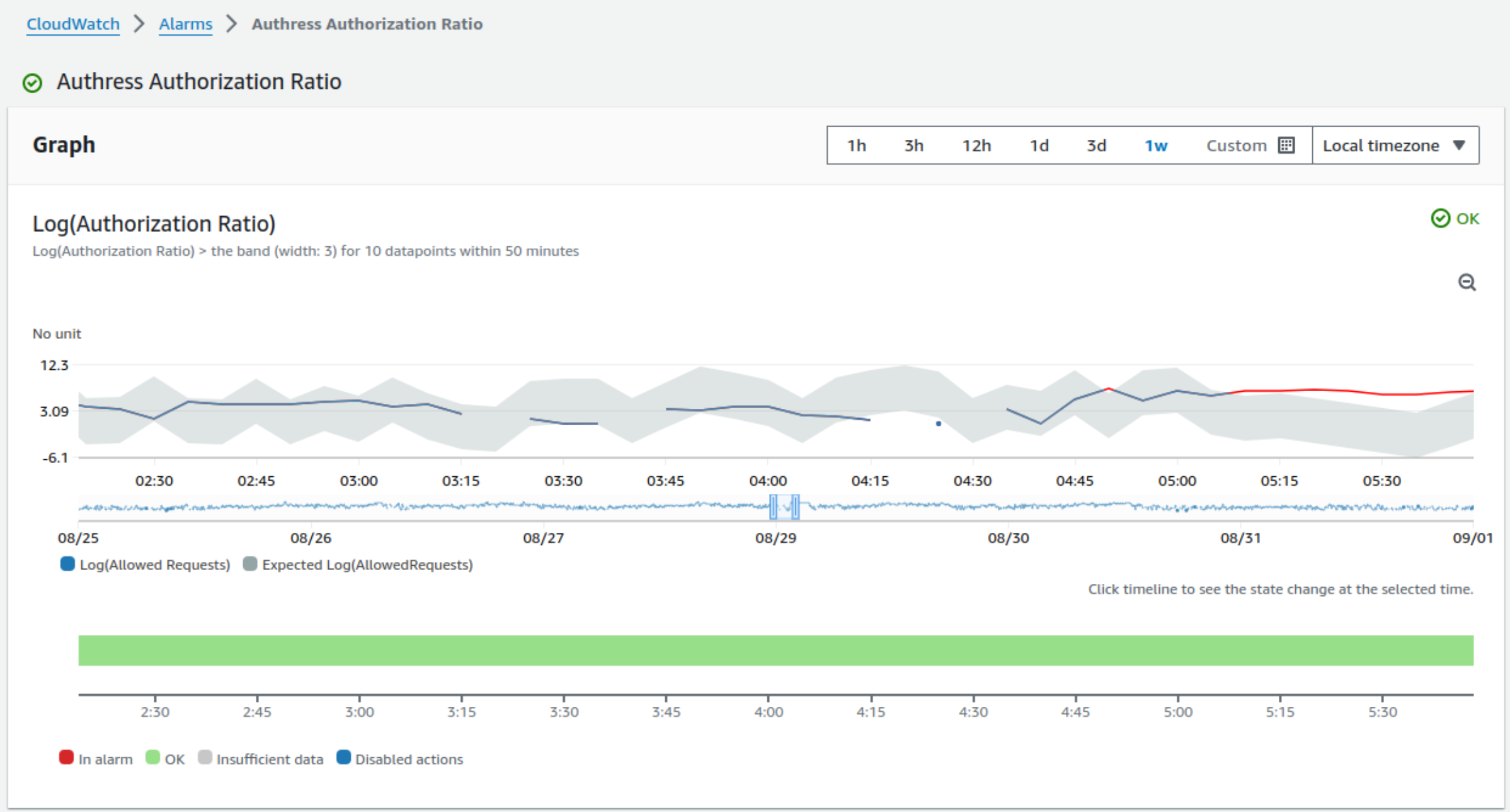
You might notice that it's not tracking 400s or 500s, which are in reality relatively easy to detect. But in fact don't actually tell us meaningfully what's wrong with our service or whether or not there really is a problem. Impact is measured by business value, not technical protocol level analytics, so we need to have a business-focused metric.
And for us, at Authress, the business-focussed metric we use to identify meaningful incidents we call: The Authorization Ratio. That is the ratio of successful logins and authorizations to ones that are blocked, rejected, timeout or are never completed for some reason.
The above CloudWatch metric display contains this exact ratio, and here in this timeframe represents an instance not too long ago where we got really close to firing off our alert.
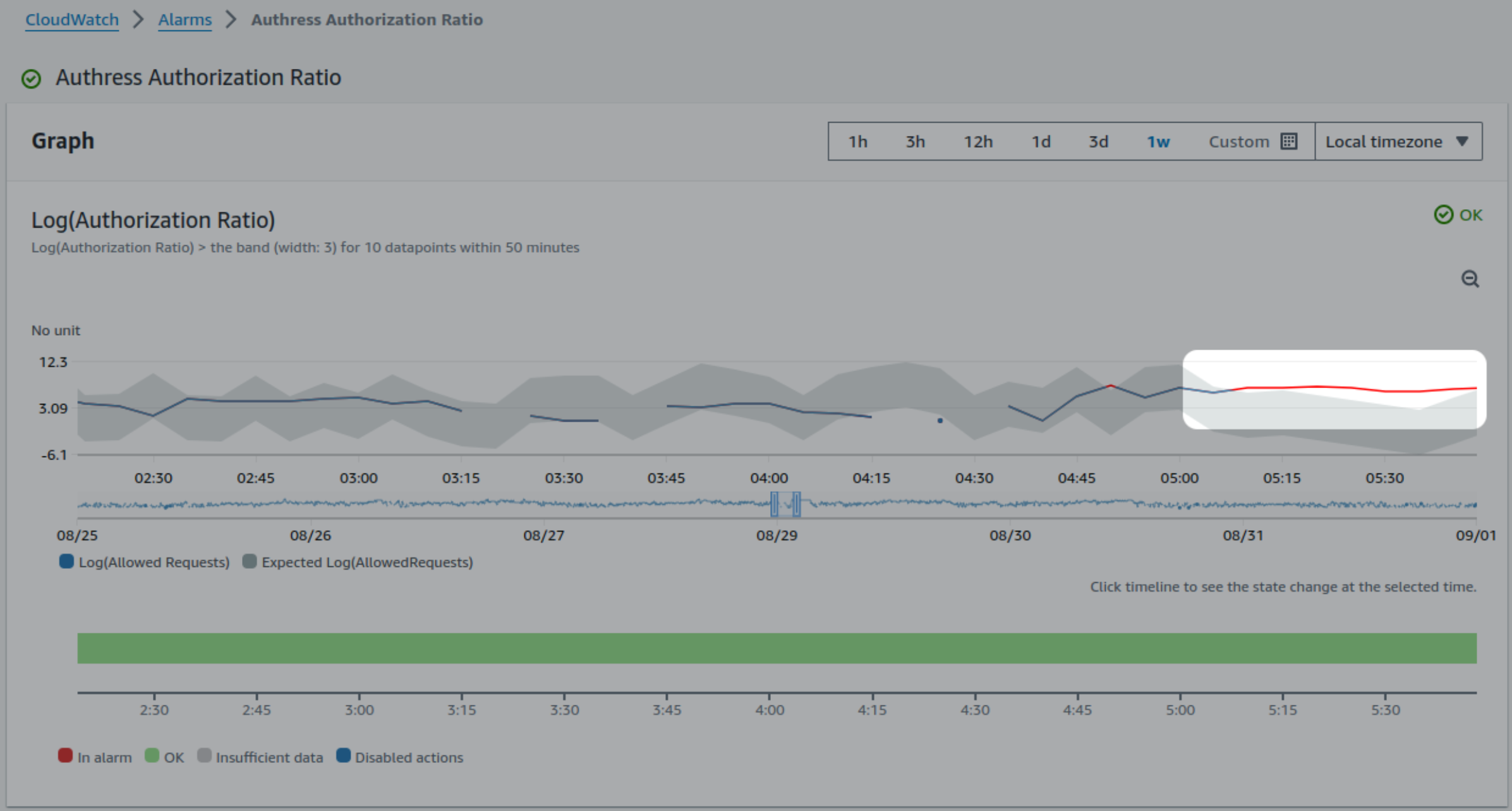
Here, there was a slight elevation of errors soon after a deployment. The expected ratio was outside of our allowance span for a short period of time. However not long enough to trigger an incident. We still investigated, but it wasn't something that required immediate remediation. And it's a good reminder that identifying problems in any production software isn't so straightforward. To achieve high reliability, we've needed an AI or in this case anomaly detection to actually identify additional problems. And realistically, even with this level of sophistication in place, we still can never know with 100% certainty that there is actually an incident at any moment. And that's because "what is an incident", is actually a philosophical question...
🌹 Does it smell like an incident?
Our anomaly detection said – almost an incident, and we determined the result – no incident. But does that mean there wasn't an incident? What makes an incident, how do I define an incident? And is that exact definition ubiquitous, for every system, every engineer, every customer?
Obviously not, and one look at the AWS Health Status Dashboard is all you need to determine that the identification of incidents is based on subjective perspective, rather than objective criteria. What's actually more important is the synthesis of our perspective on the situation and what our customers believe. To see what I mean, let's do a comparison:
I'm going to use Authress as an example. So I've got the product services perspective on one side and our customer's perspective on the other.
Incident Alignment
In the top left corner we have alignment. If we believe that our system is up and working and our customers do, too, then success, all good. Everything's working as expected.
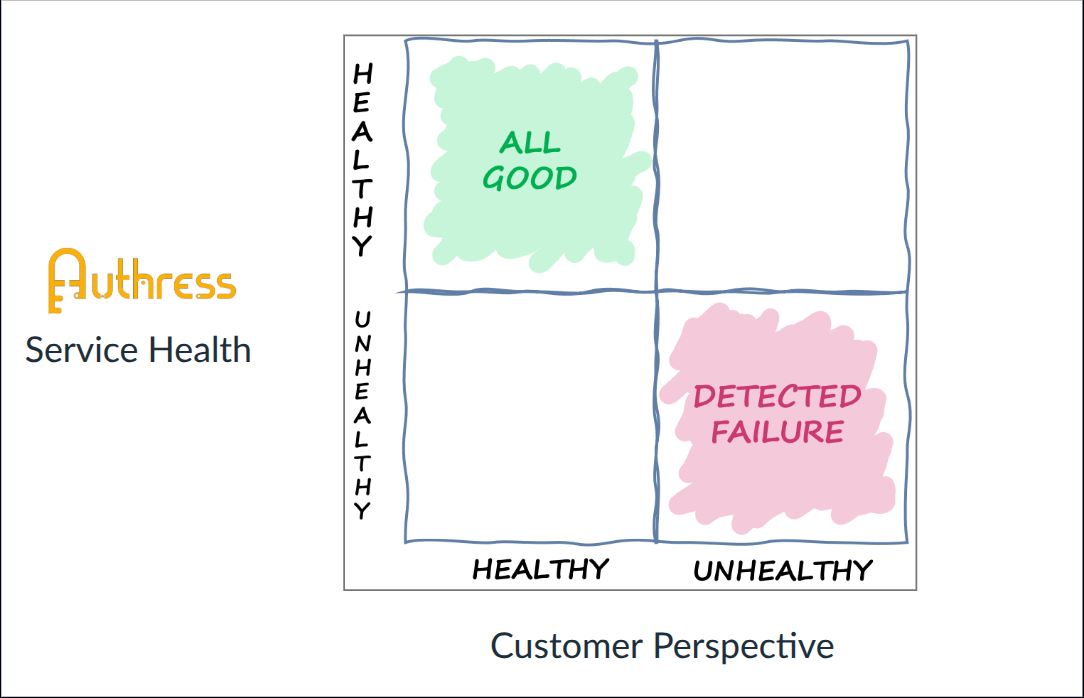
Inversely in the opposite corner, maybe there is a problem. We believe that one of our services is having an issue, and successfully, we're able to identify it. Most importantly, our customers say–yes, there is an issue for us.
It's not great that there's an incident, but as I've identified incidents will absolutely happen, and the fact we've correctly aligned with our customers on the problem's existence independently allows us to deploy automation to automatically remediate the issue. That's a success! If it's a new problem that we haven't seen before, we can even design new automation to fix this. Correctly identifying incidents is challenging, so doing that step correctly, leads itself very well to automation for remediation.
Perspective Mismatch
One interesting corner is when our customers believe that there's nothing wrong, there have been no incidents reported, but all our alerts are saying – RED ALERT — someone has to go look at this!
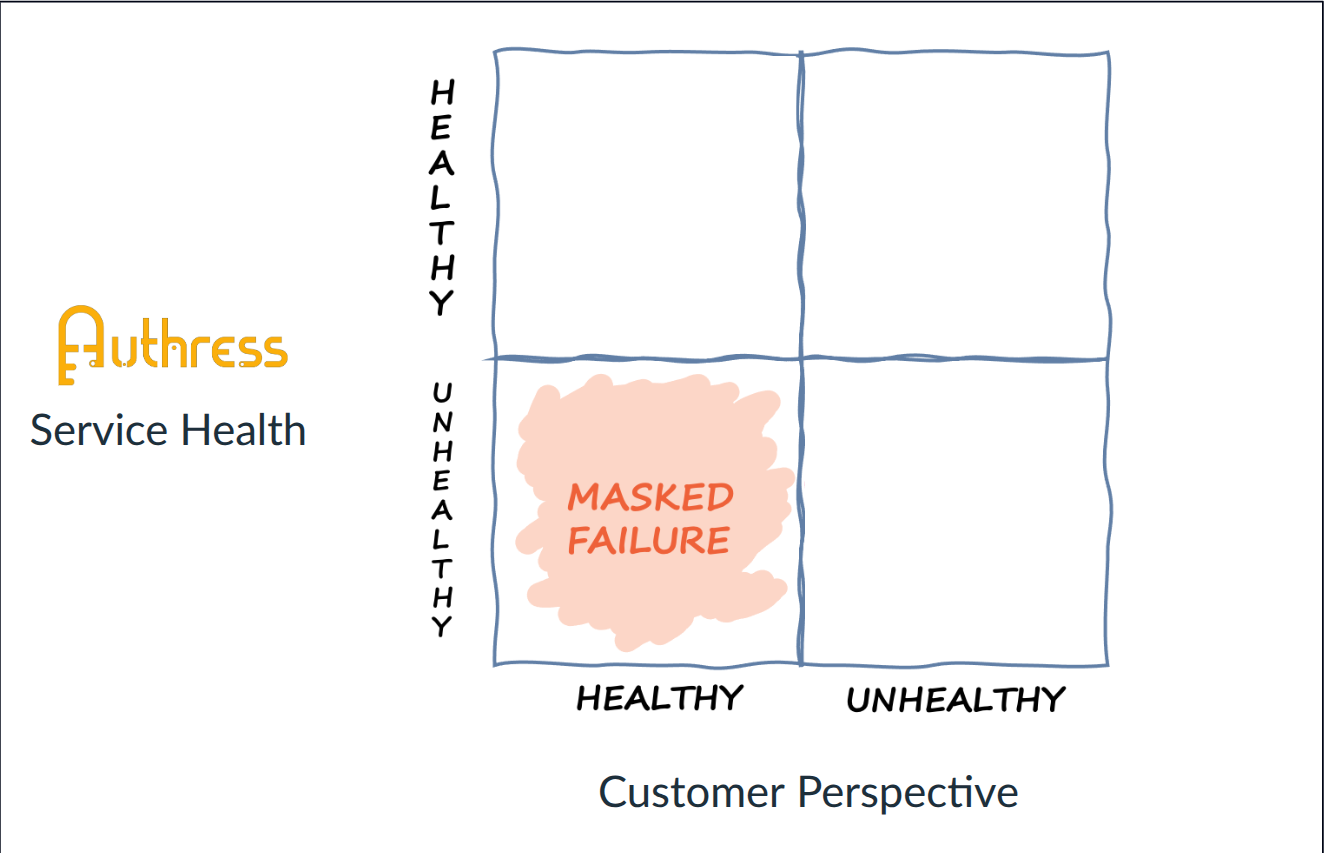
In this case, our alerts have identified a problem that no one cares about. This often happens in scenarios where our customers are in one region, Switzerland for example, with local region users, a health care, manufacturing, or e-commerce app, is a good example, rather than global, who are likely asleep at 2:00 AM. And that means an incident at the moment, could be an issue affecting some customers. But if they aren't around to experience it, is it actually happening?
You are probably wincing at that idea. There's a bug, it must be fixed! And sure that's a problem, it's happening and we should take note of what's going on. But we don't need to respond in real time. That's a waste of our resources where we could be investing in other things. Why wake up our engineers based on functionality that no one is using?
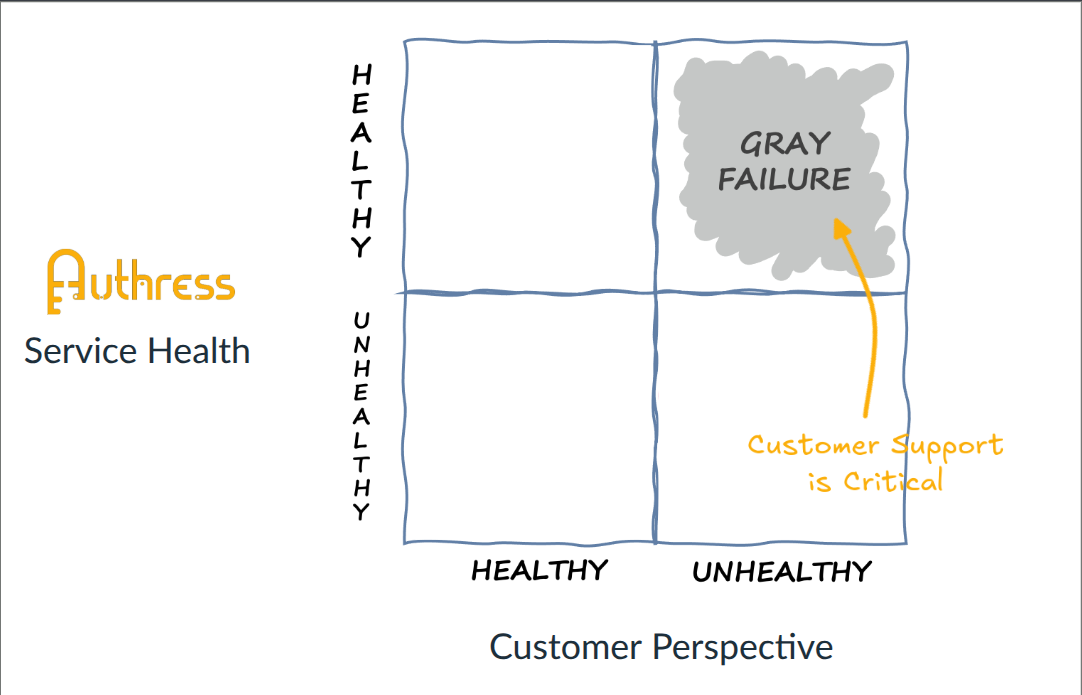
I think one of the most interesting categories is in the top right-hand corner where:
- our customers say, "hey, your service is down"
- But we say, "Wait, really, is it?"_
This is known as a gray failure.
Gray Failures
And it can happen for any number of reasons. Maybe there is something in our knowledge base that tells our customers to do something one way and it's confusing and they've interpreted it in a different way. So there's a different expectation here. That expectation can get codified into customer processes and product services.
Or maybe our customer is running different tests from us, ones that are of course, valuable for their business, but not ones that we consider. Or more likely they are just using a less resilient cloud provider.
Most fundamentally, there could really be an incident, something that we haven't detected yet, but they have. And if we don't respond to that, it could grow, and left unchecked, escalate, and eventually impact all our customers. This means we need to give our customers an easy way to report incidents to us, which we can immediately follow up with.
For us, every single incident, every single customer support ticket that comes into our platform, we immediately and directly send it to our engineering team. Now, I often get pushback on this from other leaders. I'm sure, even you might be thinking something like — I don't want to be on call for customer support incidents. But if you throw additional tiers in your organization between your engineering teams and your customers, that means you're increasing the time to actually start investigating and resolving those problems. If you have two tiers before your engineering team and each tier has its own SLA of 10 minutes to triage the issue, that means you've already gone through 20 minutes before an engineer even knows about it and can go and look at it. That violates our SLA by fourfold before investigation and remediation can even begin.
Instead, in those scenarios, what I actually recommend thinking about is how might you reduce the number of support tickets you receive in aggregate? This is the much more appropriate way to look at the problem. If you are getting support tickets that don't make sense, then you've got to investigate, why did we get this ticket? Do the root cause analysis on the ticket, not just the issue mentioned in it — why the ticket was even created in the first place.
A ticket means: Something is broken. From there, we can figure out, OK, maybe we need to improve our documentation. Or we need to change what we're doing on one of our endpoints. Or we need to change the response error message we're sending. But you can always go deeper.
The customer support advantage
And going deeper, means customer support is critical for us. We consider customer support to be the lifeline of our service level agreement (SLA). If we didn't have that advantage, then we might not have been able to deliver our commitment at all. So much so that we report some of our own CloudWatch custom metrics to our customers so they can have an aggregate view of both what they know internally and what we believe. We do this through our own internal dashboard in our application management UIs.
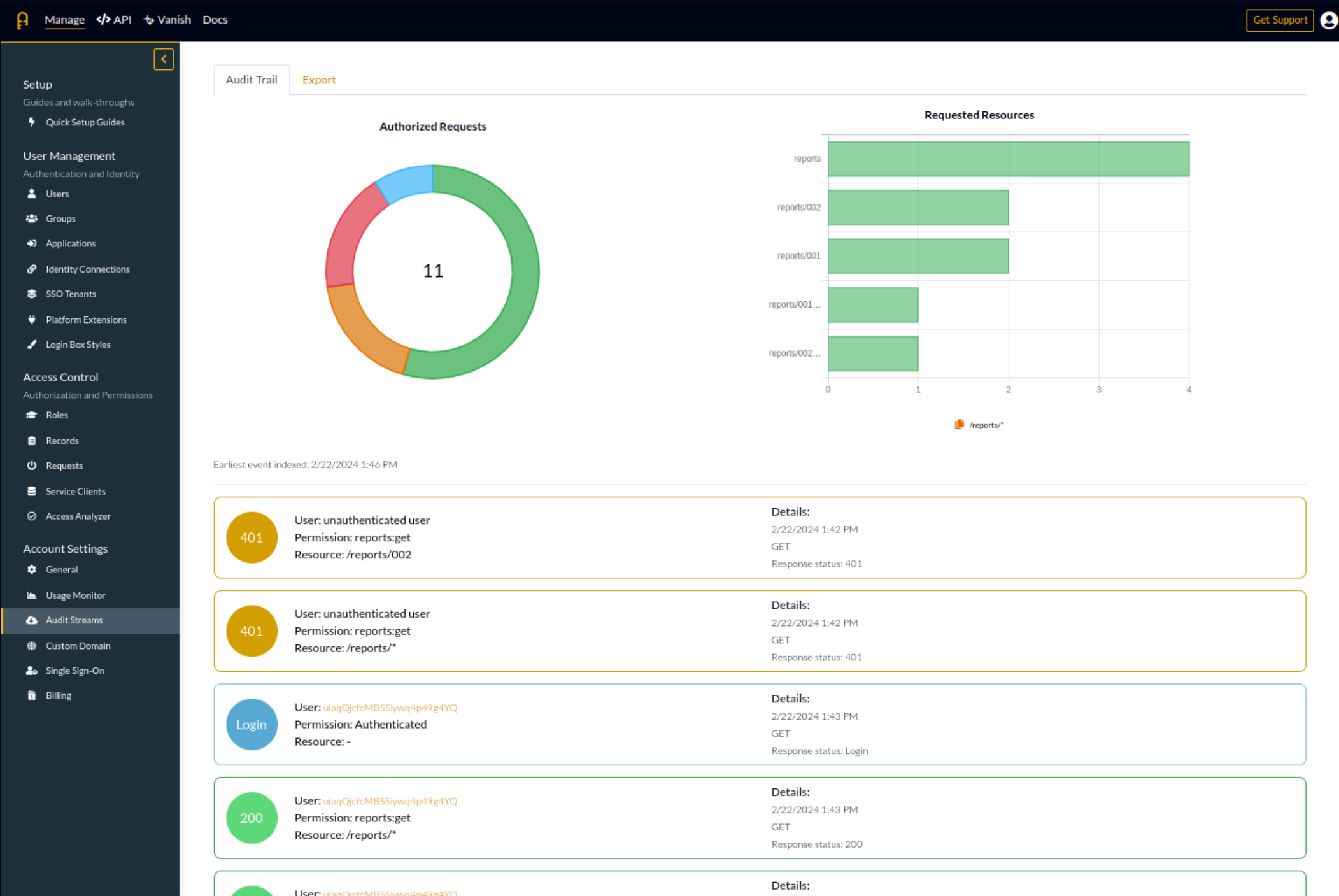
Helping our users identify incidents benefits us; because we can't catch everything. It's just not possible.
💀 Negligence and Malice
To this point, we've done the math on reliability of third-party components. We've implemented an automatic region failover and added incremental rollout. And we have a core customer support focus. Is that sufficient to achieve 5-nines of reliability?
If you think yes, then you'd expect the meme pictures now. And, I wish I could say it was enough, but it's not. That's because we also have to deal with negligence and malice.
We're in a privileged position to have numerous security researchers out there on the internet constantly trying to find vulnerabilities within our service. For transparency, I have some of those reports I want to share:
“Real” Vulnerability Reports
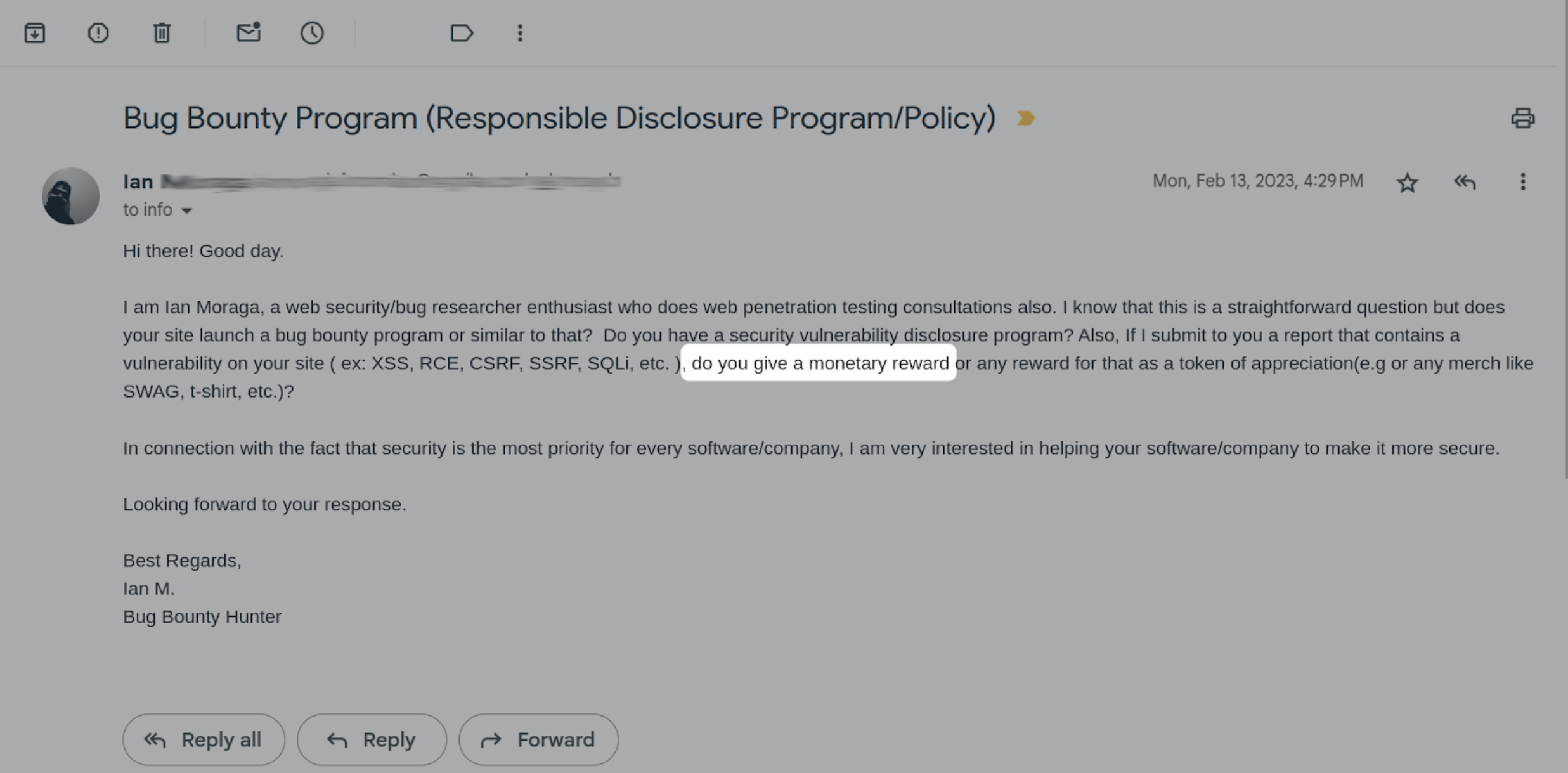
I am a web security researcher enthusiast. Do you give a monetary reward?
Okay, this isn't starting out that great. What else have we received?
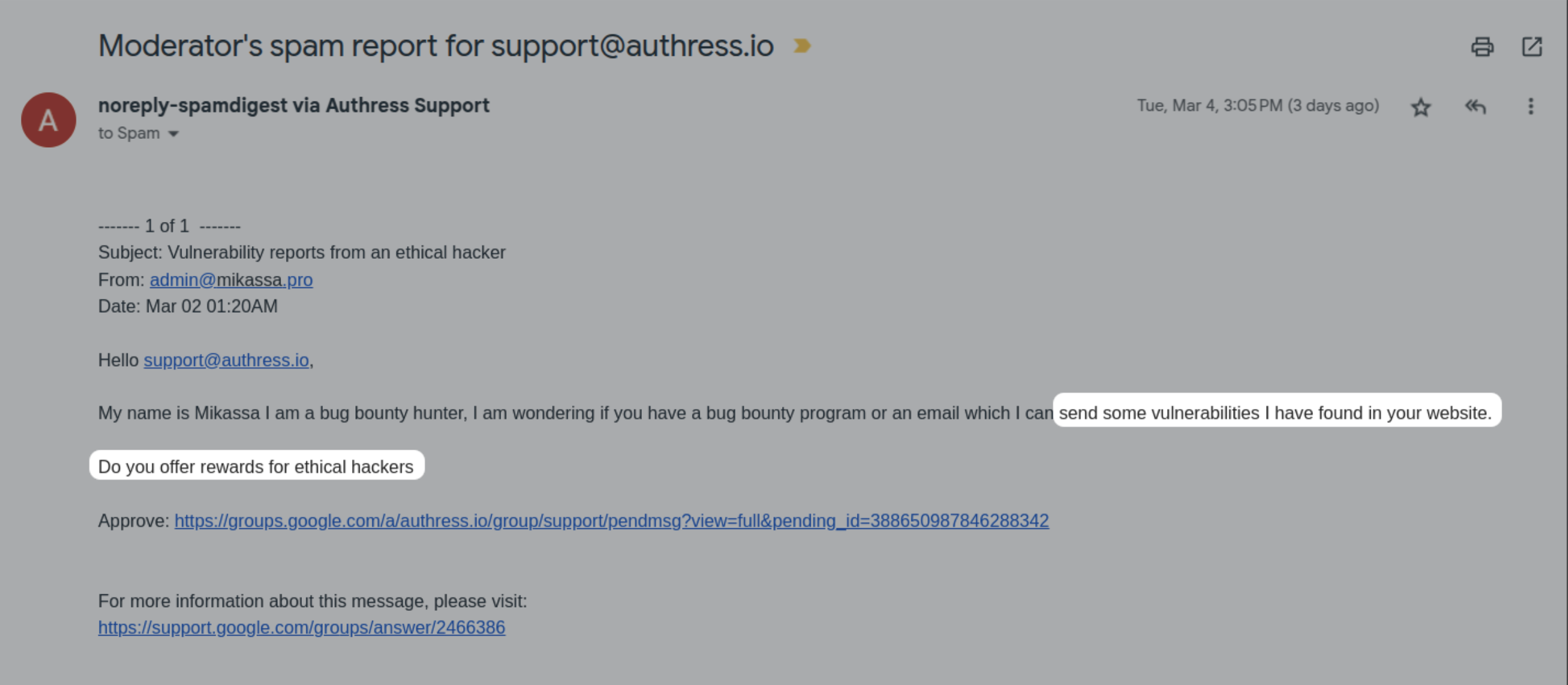
I found some vulnerabilities in your website. Do you offer rewards for ethical hackers?
Well, maybe, but I think you would actually need to answer for us, what the problem actually is. And you also might notice this went to our spam. It didn't even get to our inbox. So a lot of help they might be providing. Actually we ignore any ”security” email sent from a non-custom domain.
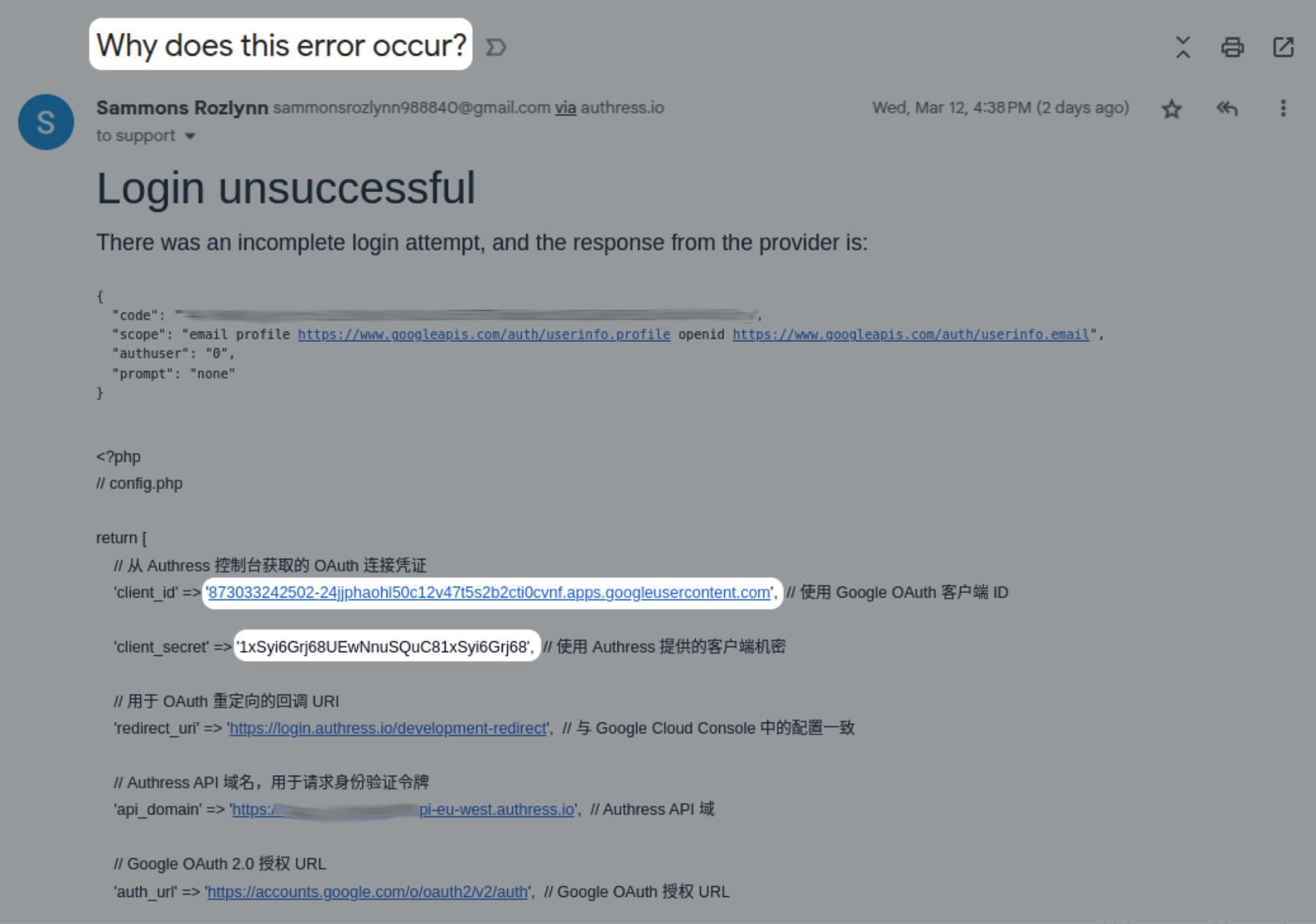
This one was really interesting. We had someone attempting to phish our engineering team by creating a support ticket and putting in some configuration trying to get us to provide them our own credentials to one of our third-party dependencies. Interestingly enough, our teams don't even have access to those credentials directly.
And, we know this was malicious because the credentials that they are referencing in the support request are from our honey pot, stuck in our UI to explicitly catch these sorts of things. The only way to get these credentials is if they hacked around our UI application and pulled out of the HTML. They aren't readily available any other way. So it was very easy for us to detect that this “report” was actually a social engineering attack.
And this is one of my favorites, and I can't make this up:
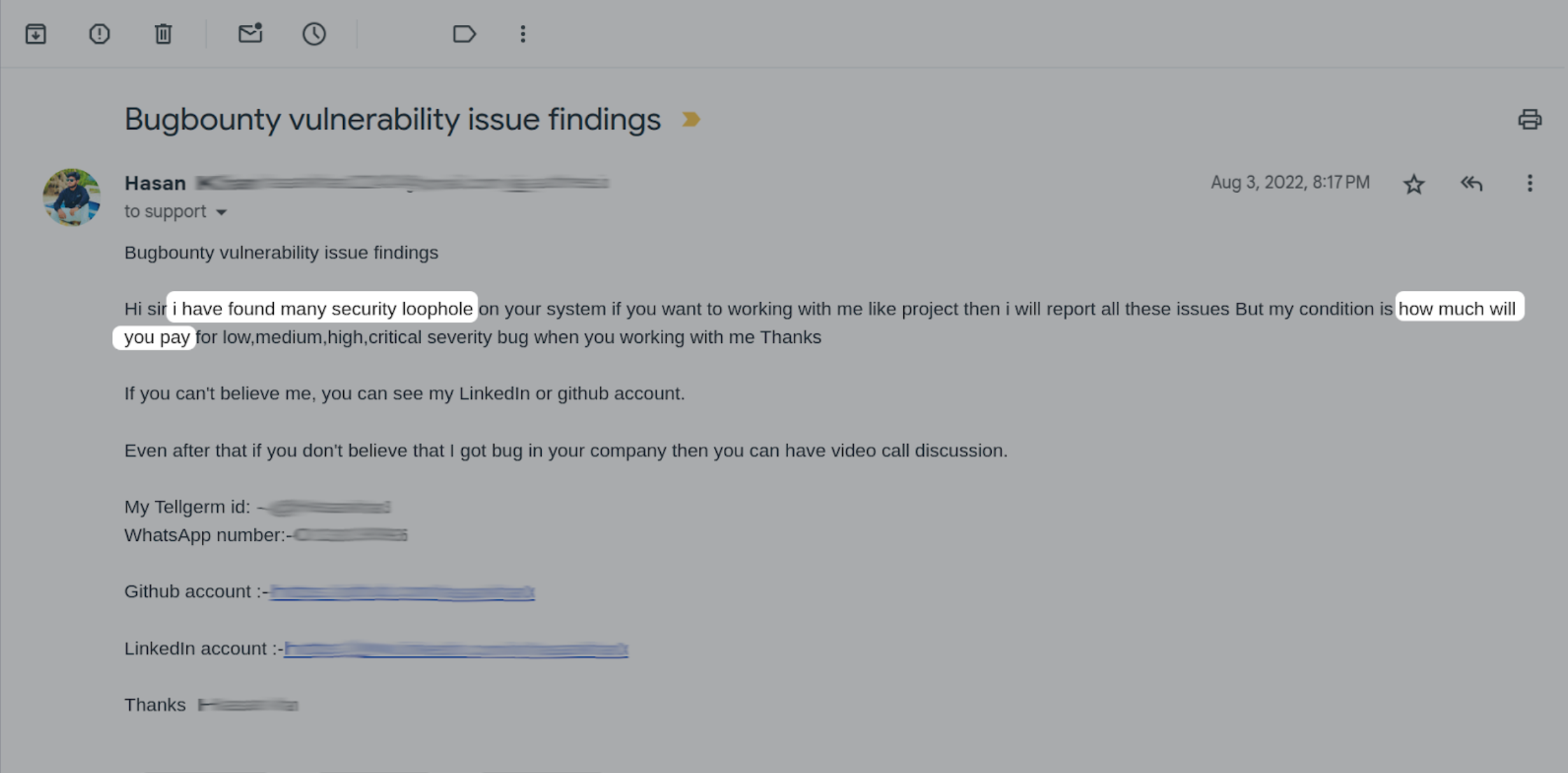
I have found many security loophole. How much will you pay if you want to working with me like project?
That's the exact quote, I don't even know what that means. Unfortunately, LLMs will actually start to make all of these future "vulnerability reports" sound more appealing to read in the future, for better or worse. However, at the end of the day, the truth is that these are harmless. And we actually do have a security disclosure program that anyone can go and submit problems for. I hope the message to white-hat hackers is please use that process, and the legitimate reports usually do go through it. Do not send us emails. Those are going to go into the abyss. Alternatively, you can follow our security.txt public page or go to the disclosure form, but with email, the wrong people are going to get that and we can't triage effectively.
Vulnerabilities in our services can result in production incidents for our customers. That means security is part of our SLA. Don't believe me, I'll show you how:
Multitenant considerations
It's relevant for us, that Authress is a multitenant solution. So some of the resources within our service are in fact shared between customers.
Additionally, customers could have multiple services in a microservice architecture or multiple components. And one of these services could theoretically consume all of the resources that we've allocated for that customer. In that scenario, that would cause an incident for that customer. So we need to protect against resource exhaustion Intra-Tenant. Likewise, we have multiple customers. One of those customers could be consuming more resources than we've allocated to the entire tenant. And that could cause an incident across Inter-Tenant and cause an incident across our platform and impact other customers.
Lastly, we have to be worried about our customers, our customers' customers, and our customers' customers' customers, because any one of those could be malicious and consume their resources and so on and so forth, thus causing a cascading failure. A failure due to lack of resources is an incident. The only solution that makes sense for this is, surprise, rate limiting.
Helpful Rate Limiting
So we need to rate-limit these requests at different levels for different kinds of clients, different kinds of users, and we do that within our architecture, at different fundamental levels within our infrastructure.
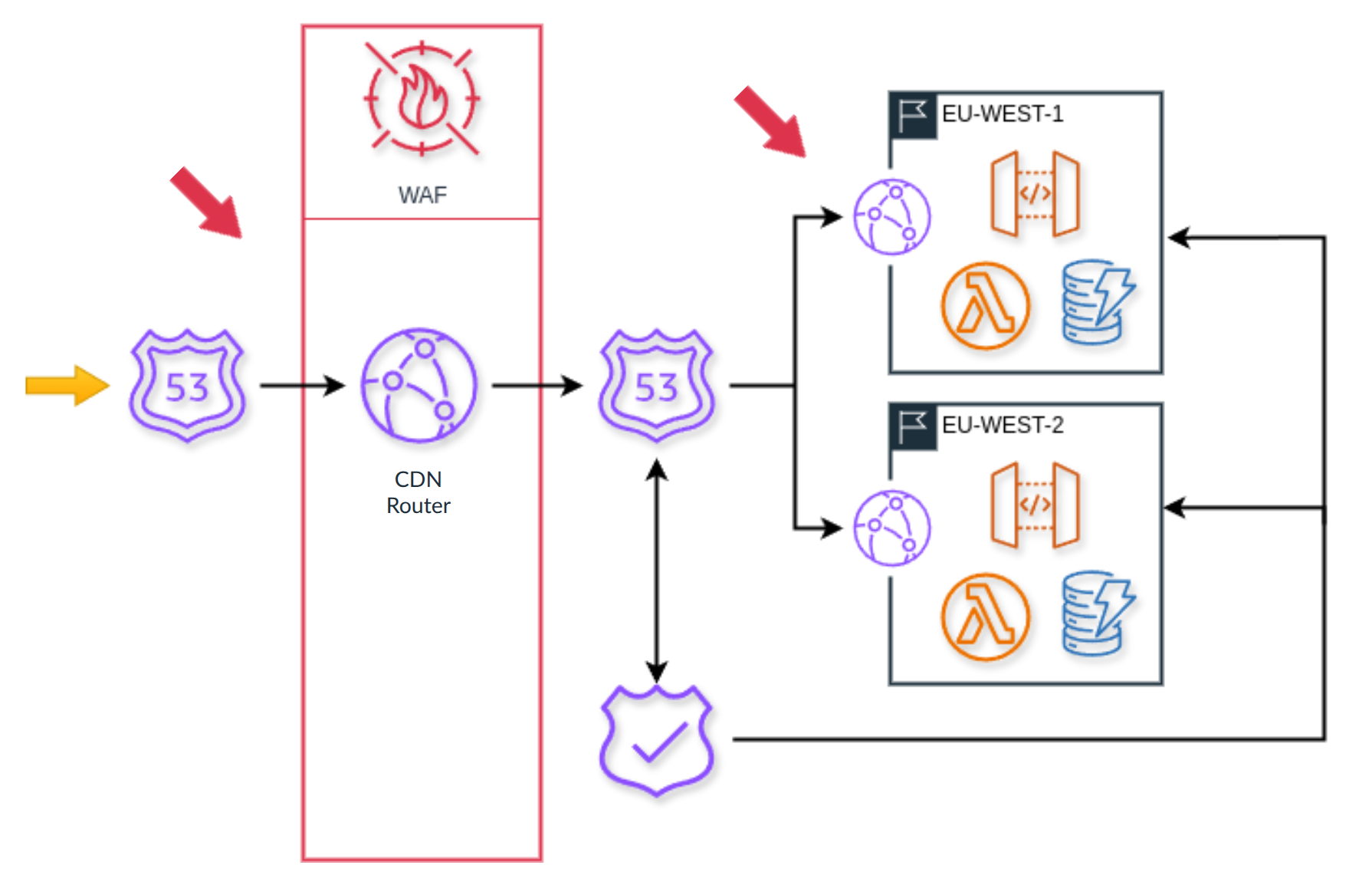
Primarily there are protections at our compute level, as well at the region level, and also place protections at a global level. In AWS, this of course means using a web application firewall or WAF. I think our WAF configuration is interesting and in some ways novel.
Fundamentally, one of the things that we love to use is the AWS managed IP reputation list.
The reputation list is list of IP addresses that have been associated with malicious activity outside of our service throughout other customers at AWS and other providers out there in the world where a problem has been detected. That means before those attacks even get to our service or to our customers' instances of Authress, we can already know to block them, and the WAF does that. This is great, and most importantly, has a very low false positive rate.
However, the false positive rate is an important metric for consideration of counter measures against malicious attacks or negligent accidental abuse of resources, and something that prevents us from using any other managed rules from AWS or external providers. There's two problems with managed rules, fundamentally:
- Number one is the false positive rate. If that is even a little bit more, it couldn't be sustainable, and would result in us blocking legitimate requests coming for a customer. This means it is a problem, and it's an incident for them if some of their users can't utilize their software because of something we did. False positives are customer incidents.
- The second one is that managed rules are gratuitously expensive. Lots of companies are building these just to charge you lots of money, and the ROI just doesn't seem to be there. We don't see useful blocks from them.
But the truth is, we need to do something more than just the reputation list rule.
Handling Requests at Scale
And the thing that we've decided to do is — add blocking for sufficiently high requests. By default, any Authress account's service client that goes above 2,000 requests per second (RPS), we just immediately terminate. Now, this isn't every customer, as there are some out there for us that do require such a high load or even higher (as 2k isn't that high). But for the majority of them, if you get to this number and they haven't talked to us about their volume, then it is probably malicious in some way. You don't magically go from zero to 2,000 one day, unless it is an import job.
Likewise, we can actually learn about a problem long before it gets to that scale. We have milestones, and we start reporting loads from clients at 100, 200, 500, 1,000, et cetera. If we see clients hitting these load milestones, we can already start to respond and create an incident for us to investigate before they reach a point where they're consuming all of the resources in our services for that customer. And we do this by adding alerts on the COUNT of requests for WAF metrics.
However, we also get attacks at a smaller scale. Just because we aren't being DDoS-ed doesn't mean there isn't attack. And those requests will still get through because they don't meet our blocking limits. They could be malicious in nature, but only identifiable in aggregate. So while single request might seem fine, if you see the same request 10 times a second, 100 times a second, something is probably wrong. Or if you have request urls that end in .php?admin, when no one has run WordPress in decades, you also know that there's a problem. We catch these by logging all of the blocked requests.
We have automation in place to query those results and update our rules, but a picture is worth a thousand words:
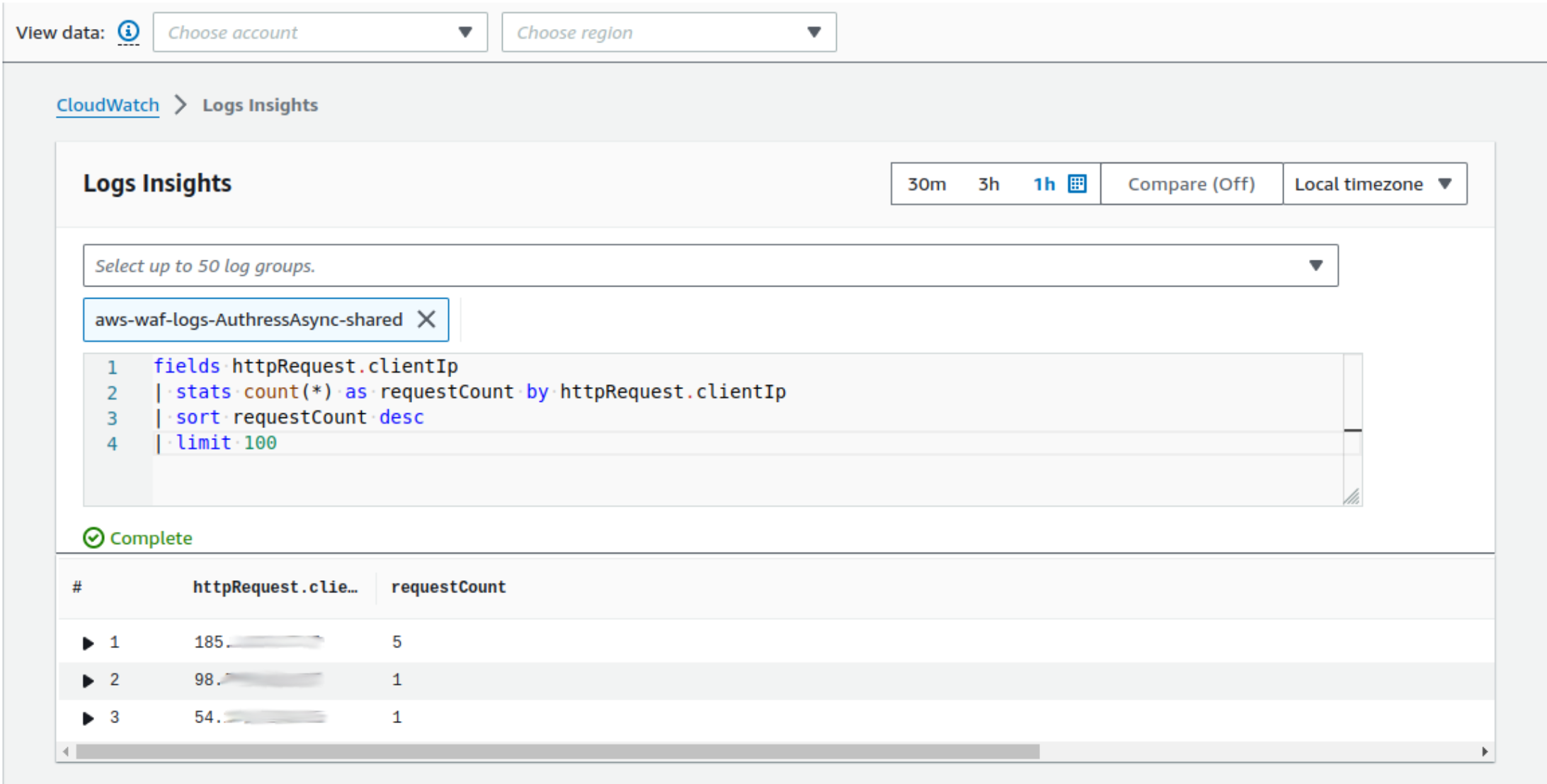
Here you can see a query based off of the IP addresses from the client that are being utilized and sorted by frequency. When we get these requests that look non-malicious individually, we execute a query such as this one and we check to see if the results match a pattern. You can use ip address matching or more intelligently, something called the JA3 or JA4 fingerprints of those requests There are actually lots of options available, I'm not going to get into exactly what they are, there are some great articles on the topic. And there are more mechanisms to actually track these used throughout the security industry, and utilizing them let's you instantly identify: Hey, you know what? This request violates one of our patterns, maybe we should block all the requests from that client.
And so, rather than waiting for them to get to the point where an attacker is consuming 2,000 requests per second worth of resources, you can stop there right away. In the cases where we can't make a conclusive decision, this technology gives us another tool that we can utilize to improve our patterns for the future. Maybe it goes without saying, but of course because we've running our technology to many regions around the world, we have to work on deploying this infrastructure in all these places and push it out to the edge where possible.
🎁 The Conclusion
I said a lot of things, so I to quickly want to quickly summarize our architecture that we have in place:
- Third-party component reliability reviews. I can't stress this enough. Don't just assume that you can utilize something. And sometimes in order to achieve 5-nines, you actually have to remove components from your infrastructure. Some things are just not able to be utilized no matter what. Now maybe you can put it in some sort of async background, but it can't be on the critical path for your endpoints.
- DNS failover and health checks. For places where you have an individual region or availability zone or cluster, having a full backup with a way to conclusively determine what's up and automatically failover is critical.
- Edge compute where possible. There's a whole network out there of services that are running on top of the cloud providers, which help guarantee your capability to run as close to as possible to where your users are and reduce latency.
- Incremental rollout for when you want to reduce the impact as much as possible.
- The Web Application Firewall for handling those malicious requests.
- Having a Customer Support Focus to enable escalating issues that outside your area of detection.
And through seven years or so that we've been doing this and building up this architecture, there's a couple of things that we've learned:
Murphy's Law
Everything fails all the time. There absolutely will be failures everywhere. Every line of code, every component you pull in, every library, there's guaranteed to be a problem in each and everyone of those. And you will for sure have to deal with it, at some point. So being prepared to handle that situation, is something you have to be thinking through in your design.
DNS
DNS, yeah, AWS will say it, everyone out there will say, and now we get to say it. The global DNS architecture is pretty good and reliable for a lot of scenarios, but I worry that it's still a single point of failure in a lot of ways.
Infrastructure as Code (IAC)
The last thing is infrastructure as code challenges. We deploy primary regions, but then there's also the backup regions, which are slightly different from the primary regions, and then there are edge compute, which are, again, even more slightly different. And then sometimes, we do this ridiculous thing, where we deploy infrastructure dedicated to one customers. And in doing so, we're running some sort of IaC to deploy those resources.
It is almost exactly the same architecture. Almost! Because it isn't exactly the same there are quite the opportunities for challenges to sneak it. That's problematic with even Open Tofu or CloudFormation, and often these tools make it more difficult, not less. And good luck to you, if you're still using some else that hasn't been modernized. With those, it's even easier to run into problems and not get it exactly correct.
The last thing I want to leave you with is, well, With all of these, is that actually sufficient to achieve five nines?
No. Our commitment is 5-nines, what we do is in defense of that, just because you do all these things doesn't automatically mean your promise of 5-nines in guaranteed. And you know what, you too can promise a 5-nines SLA without doing anything. You'll likely break your promise, but for us our promise is important, and so this is our defense.
For help understanding this article or how you can implement auth and similar security architectures in your services, feel free to reach out to me via the community server.