
It shouldn't be any surprise that we rely on DynamoDB over at Authress for a variety of things. For context, we have a any number of databases of different types, and DynamoDB is just one of the ones we use. As we operate at significant scale, that means we are privileged with the opportunity to test the limits of our tools, of which DynamoDB is one.
To get to the scale we are at, with the reliability we need for our customers, idempotency is table stakes.
Failures will happen, and they will happen in every component. That means DynamoDB will fail and that means retries. We need some way to have hundreds of thousands RPS be idempotent and be retried without requiring serial processing. However, the pure RPS that needs to be idempotent does not need to be as high. That's because, while our service RPS is much higher, individual item write RPS is much lower. This might be in the range of only 100 RPS. The probability of the same item being updated more than 100 times per second is unlikely and out of scope for our service, and more importantly this article.
A good example of this is bank transactions. While some banks might have millions+ RPS, the number of finance transactions per account is usually low, and can often even be serialized. How many payments or withdrawals do you have per day? 1? 10 max? Actually for the purposes of bank accounts, what is even more important is serialization to ensure that the account does not overdraft. That is, a bank needs to prevent an account from withdrawing funds that it does not have.
I honestly hadn't expected this to be surprising, but apparently it isn't that obvious how to actually achieve this sort of idempotency in DynamoDB, so the rest of this article reviews our use case, and exactly what we do to achieve idempotent requests into DynamoDB without using DynamoDB transactions.
The setup
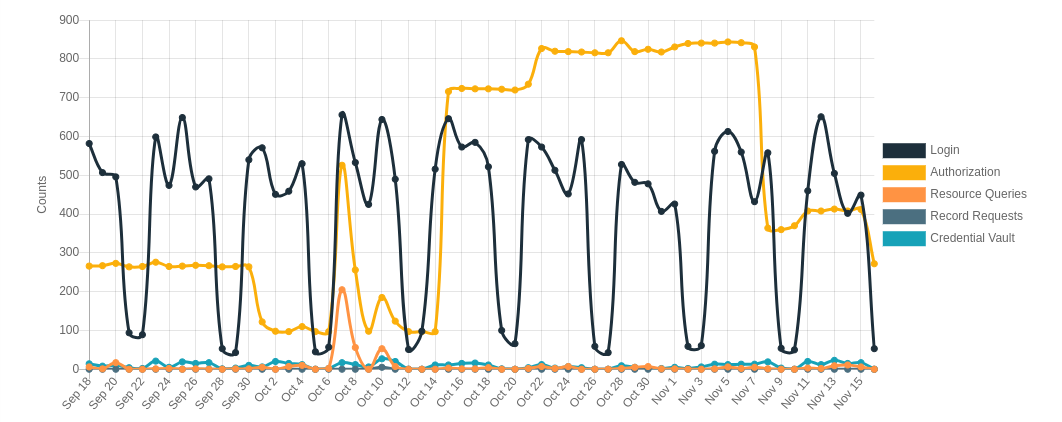
Authress provides login and access control for the apps you write. Therefore it is infrastructure, and rather than charging by some ridiculous metric like Monthly Active Users, we charge by usage. You get what you pay for. However, this means we have the unique problem of actually trying to calculate exactly how many logins and authorization requests there were, so that we can bill for it.
And more importantly we need to display this data in an aesthetically pleasing way to our customers:
The DynamoDB use case
Multiple writes are going to come into your table at the same time. Before we can even get to the actual use case with handling idempotency, I want to review all the different ways concurrent writes could be an issue for you.
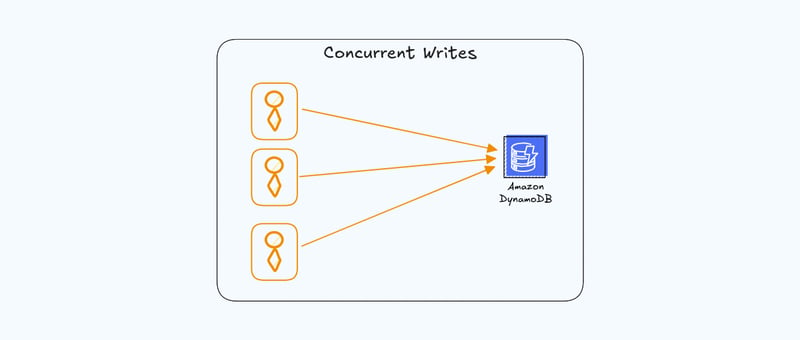
Normally, each user would likely be writing to the same table, but different items. (For simplicity, I'm going to model this the DynamoDB requests using pseudo code and javascript, of course the examples could be in any language).
await writeToTable(Table1, { pk: 'user_001' }, dataOne);
await writeToTable(Table1, { pk: 'user_002' }, dataTwo);
await writeToTable(Table1, { pk: 'user_003' }, dataThree);
This is the simplest and works out of the box. Even in more complex scenarios DynamoDB works out of the box.
Concurrent writes to same item.
await writeToTable(Table1, { pk: 'user_001' }, dataOne);
await writeToTable(Table1, { pk: 'user_001' }, dataTwo);
If we did this, then the last write would win. The problem here is that we usually care about ordering these writes. Luckily DDB supports ordered writes. All we need to do is first fetch the data before writing, and use a condition key.
const currentData = await readFromTable({ pk: 'id' });
await writeToTable({ pk: 'id' }, newData, currentData.expectedLastUpdatedDateTime);
// Or in explicit DynamoDB Syntax:
await dynamoDB.put({
Item: {
data: newData,
lastUpdated: now.toISO()
},
ConditionExpression: '#lastUpdated = :expectedLastUpdated',
ExpressionAttributeNames: {
'#lastUpdated': 'lastUpdated'
},
ExpressionAttributeValues: {
':expectedLastUpdated': currentData.lastUpdated
}
});
With more than one process writing to the same table, we could end up with either:
- read1, write1, read2, write2
- read1, read2, write1, write2
In the case of the first one, the updates will be in serial so everything is fine. (And if this were something where it wouldn't be fine, then you would use a user supplied value of the expectedLastUpdated time instead of the one from the previous read.)
In the second case, the latter write will get a ConditionalCheckFailedException exception from DDB, and you can decide what to do. In many cases, the right thing to do is retry:
- read1, read2, write1, write2 (fail)
- Retry => read2, write2 (success)
In other cases, you will want to throw the error back to the user.
Caveats
We still haven't reached the goal of this article, but even at this point there are some concerns. For instance, you can't just read the DB and then perform another write. You absolutely need to consider, what the correct outcome should be. Sometimes the correct outcome is "409 Conflict" or "412 Precondition Failed" when the user needs to take action. Other times, these updates are orthogonal. For instance, let's say there are two properties A and B.
Request One updates A and Request Two updates B. In some scenarios, these might be independent properties, and so both can be persisted. In other scenarios, B should be calculated based on the current value of A, so a recalculation will work. However, if B's value should be determined by a process outside of the database, you want to throw the 4XX status code for the user to decide what to do.
The real scenario
And that is good and all, but now it is time to discuss the real scenario. What happens when DDB encounters an issue? Or the connection to DDB fails? Or the electricity powering the virtual machine where your process is running fails and terminates the compute container. Was the data in the database actually updated?
With direct persistence, or PUT semantics, you can just rerun some code (because the end result is fixed) However, when you are updating the item properties you could run into a problem because the end result is deterministic based on the current values.
So, let's go back to the Authress example. One user completed 10 api calls to Authress and now we want to record this information in the database.
Our code looks like this:
const currentValue = await readFromTable({ pk: 'id' });
await writeToTable({ pk: 'id' },
currentValue + 10,
currentData.lastUpdated);
Notice the issue?
At a small scale, this isn't an issue because with concurrent execution we can throw and retry later. However, there are actually two problems here:
- With scale of say 10 concurrent requests, 1 will succeed, but the other 9 will fail the first time, then 8 will fail the second time (after the retry), and etc... We might be able to be clever with "when" we execute the retry, but when we are unlucky for N updates, it would take N2 requests to DDB, with `N2 - N` failing. That's pretty bad.
- We have the critical problem of tracking, in the case when there is a connection drop we have no idea if the
+ 10was applied or not.
Idempotency
The only solution is to tell DDB to only process the + 10 if it wasn't processed before. So we need code that looks like this:
await writeToTable({ pk: 'id' }, 10, updateId);
We can't rely on passing in the currentValue because that violates problem (1) work at scale and only apply once. And we need to have an updateId to handle problem (2).
But DynamoDB doesn't support idempotency out of the box, but it does support operations to make this happen.
We will store the updateId and validate it on writes:
await dynamoDB.update({
UpdateExpression: 'SET #history =
list_append(#history, :keyList)',
ConditionExpression: 'NOT contains(#history, :key)',
ExpressionAttributeNames: {
'#history': 'history'
},
ExpressionAttributeValues: {
':key': idempotencyKey,
':keyList': [idempotencyKey] // DDB requires array
},
});
Getting to scale
This will work for any small scale. It handles idempotency for anything where the size of the item remains under 400KB. 400KB is the max size of a DDB item. In our case we get an update from our trigger, CloudFront, fairly often, but not too often. The trigger is an id with a hash value. ECloudFrontId/authress-account-id/2024-11-22/15.dfc31777. That's 56 characters, or ~56 bytes. Which means we could stick 400KB / 56 or 7142 updates before the item fills up. (Remember we are pushing every idempotencyKey into the #history List)
However, since we index our customer billing by date, we only need the hash in the table (or for us the hour and the hash, as CloudFront doesn't provide higher granularity than an hour). That means 15.dfc31777 or 11 bytes, which amounts to 36000 updates per day or 25 billing updates per minute. CloudFront doesn't have that level of granularity, so one item per day is more than sufficient for us.
If we needed more granularity, then we could split the billing item rows in DynamoDB by hour, and then only save the hash dfc31777 (8 characters) or 50k updates per hour (14 updates per second). Even CloudFront is smarter than to do that level of reporting, but that's a problem we would love to have to deal with.
Going even further
Let's say however, that wasn't good enough for us or an item you have requires having the 100 RPS I talked about that the beginning of the article, and those updates all need to be idempotent and cannot use the lastUpdateDateTime to drive concurrency handling, then what can you do?
DynamoDB can still support this, but we have to be clever. Let's define a gauge.
A Gauge is an arbitrary limitation that helps us restrict the solution space and make the problem easier to solve. Then once we solve the problem, we will see that this is actually the general solution as well.
So our Gauge is going to be Idempotency keys only prevent duplicates in the last 5 minutes. (Curious why I picked that? It's because 5 minutes is the same ridiculously short time span that Message Deduplication IDs in SQS permits. If it is good enough for AWS, maybe it is good enough for us).
If we only need to save idempotency keys for the last 5 minutes, and we have 100 RPS, then that means we have to save 5 min * 60 seconds * 100 RPS = 30k keys.
Luckily that is below our limit, we calculated in the previous section (which came to be 50k keys), it makes you seriously wonder if DynamoDB is used with SQS deduplication...
In any case, how the heck are we going to store only the last 30k keys in the item. The answer is the magic REMOVE DynamoDB UpdateExpression Operation. DynamoDB supports REMOVING List items in a DynamoDB item List property. More details on the REMOVE operation if you are curious.
The AWS example shows this CLI command:
aws dynamodb update-item \
--table-name ProductCatalog \
--key '{"Id":{"N":"789"}}' \
--update-expression "REMOVE RelatedItems[1], RelatedItems[2]" \
--return-values ALL_NEW
Can we use that to help us here?
Yes!, Yes we can. Let's update our DDB update expression to add new idempotency keys to the end of the list, and remove the oldest one from the front:
await dynamoDB.update({
UpdateExpression: 'SET #history =
list_append(#history, :keyList)
DELETE #history[0]',
ConditionExpression: 'NOT contains(#history, :key)',
ExpressionAttributeNames: {
'#history': 'history'
},
ExpressionAttributeValues: {
':key': idempotencyKey,
':keyList': [idempotencyKey] // DDB requires array
},
});
Now when ever we add a new idempotency key to the list we also remove one from the front of the list.
However this isn't the whole solution. It is also important to remember that if there are zero elements in the list, then this will cause a problem, also we need to get to this steady state. We need 30k values in our list already. So we can do two things:
- Update the
ConditionExpressionto includeattribute_exists(#id), that will force aConditionalCheckFailedExceptionwhen it doesn't exist. - Fallback on the item not existing to creating it with a initial empty
#historyof 30k blank values.
await dynamoDB.put({
Item: {
history: [...Array(30000)].map(() => 0)
.concat(idempotencyKey)
},
ConditionExpression: 'attribute_not_exists(#id)',
ExpressionAttributeNames: {
'#id': 'id',
'#history': 'history'
}
});
And then from that moment on the list will always have every key from the last 5 minutes.
The Math
One last thing I wanted to throw in here is a formula. That is the relationship between RPS, Idempotency Key Size (Ks), and Idempotency Key Lifetime (Kl).
Given we have a limit of 400KB for a DDB item, we will have:
KeyLifetime * KeySize * RPS <= 400KB
That is if you have 10 request every second, and you want to save the keys for 10 minutes, then your key sizes are limited to
KeySize <= 400KB / (6000) = 70-byte keys
However there is one more limitation here, the size of the keys must account for significantly greater than then the number of keys that will be used. For instance, if we were allowed only 3-byte keys (which happens if we have key lifetime of 1 hour and ~40 RPS), we will have a problem. While 128*3 (ascii 7-bit) is 2097152 and much larger than the number of total keys that would be saved in your KeyList (144000), performing an optimized hashing to get from the idempotency value the user provides to one of only 3 characters, is quite a challenge. Having less than 128 byte key is usually an issue. However, you might be able to optimize by using a SHA256 hash is 32 bytes long. Which means that with a SHA256 hash for idempotency keys, your `KeyLifetime RPSwould support12500` keys. (Or only 42 RPS for 5 minute key LifeTime)
K-Byte Idempotency Keys
This graph shows the formula plotted for each of different K-Byte sizes, 32, 64, and 128, as well the maximum RPS * Lifetime you can have for each one:
Limitations
This of course has some limitations:
(1) The idempotencyKey size is limited. The SQS messageDeduplicationId is limited to 128 bytes. Ours is going to be a bit smaller
(2) At an RPS of 100, that would require a DynamoDB item to allow a size of at least 4MB to support 128-byte keys. So clearly each SQS FIFO queue is not using a single DDB item to store this. However, for a smaller Deduplication ID or a lower RPS we can easily fit everything in. For instance, even with a 128-byte keys, a customer RPS of 10 or less can fit everything in there. DDB can actually return 1MB per query, so actually AWS had more room to design this feature (if AWS wanted to use DDB to solve this problem).
(3) Our actual RPS must be <= 100, it can't be 101, even in burst, or else there will be a problem. Or more specifically, there will be a problem if a request gets dropped and requests an idempotent retry.
(4) You need to do the analysis to know what your RPS is per item and what your users and customers expect. If you are directly exposing this mechanism to a process you don't control it might actually overwhelm your database table (for example your REST API). But if you are in full control of what is happening (eg background processing), and monitor the usage, this is the perfect solution.
(5) Don't try to get too smart with DDB operations unless you really know what you are doing. Coming up with strategies like this is not simple, obvious, or quick. At Authress we spent years discovering opportunities to improve the usage and performance of our databases.